

2018年度学位論文研究 修士論文
畳み込みニューラルネットワークにおける低精度演算を用いた高速化の検証 (長沼 大樹)
Verification of speeding up using low precision arithmetic in convolutional neural network
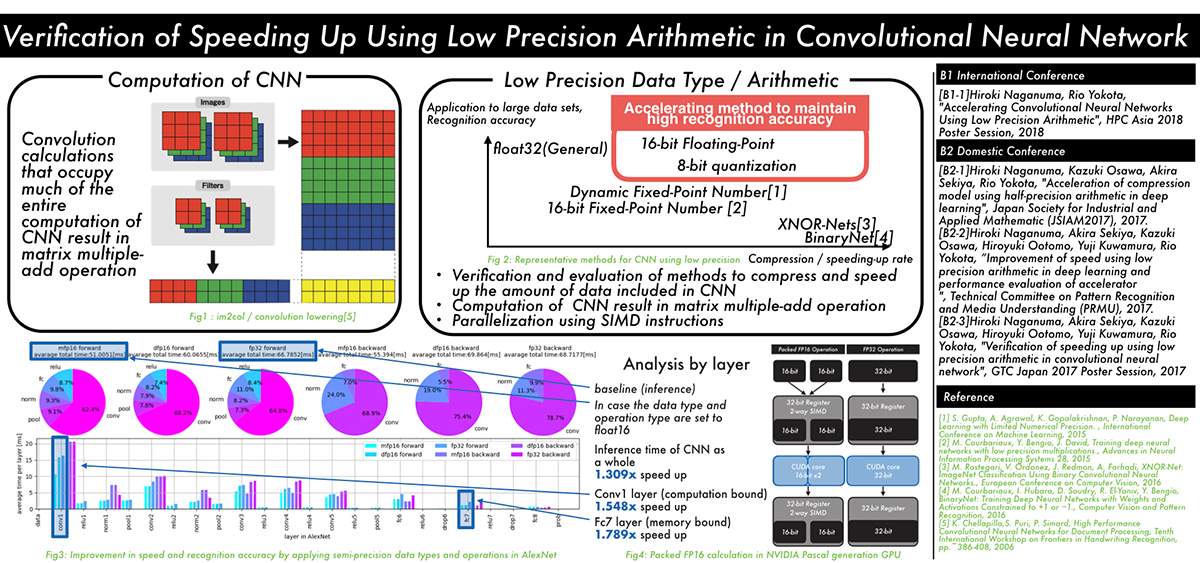
The recent trend in convolutional neural networks (CNN) is to have deeper multilayered structures. While this improves the accuracy of the model, the amount of computation and the amount of data involved in learning and inference increases. In order to solve this problem, several techniques have been proposed to reduce the amount of data and the amount of computation by lowering the numerical precision of computation and data by utilizing the CNN's resistance to noise.
However, there is a lack of discussion on the relationship between parameter compression and speedup within each layer of the CNN.
In this research, we propose a method to speed up the inference by using half precision floating point SIMD instructions, by applying low precision to the learned model, in addition to reducing the data of the CNN model, and speeding up data access for layers that are computation-bound.
We examined the influence of CNN recognition accuracy, the speedup for each layer, and its reason, when we apply our method.
▲クリックすると拡大されます
大規模並列深層学習のための確率的最適化に基づいた目的関数の平滑化 (長沼 大樹)
Smoothing of the Objective Function in Stochastic Optimization for Large Scale Parallel Deep Learning
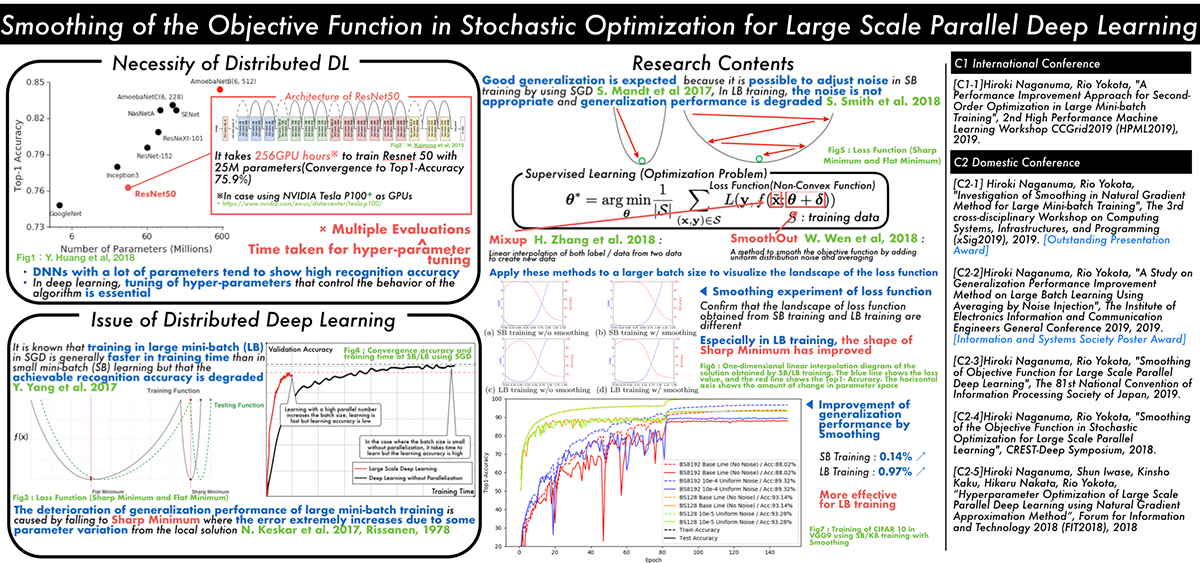
Classical learning theory states that when the number of parameters of the model is too large compared to the data, the model will overfit and the generalization performance deteriorates. However, it has been empirically shown that deep neural networks (DNN) can achieve high generalization capability by training with extremely large amount of data and model parameters, which exceeds the predictions of classical learning theory. One drawback of this is that training of DNN requires enormous calculation time. Therefore, it is necessary to reduce the training time through large scale parallelization. Straightforward data-parallelization of DNN degrades convergence and generalization. In the present work, we investigate the possibility of using second order methods to solve this generalization gap in large-batch training. This is motivated by our observation that each mini-batch becomes more statistically stable, and thus the effect of considering the curvature plays a more important role in large-batch training. We have also found that naively adapting the natural gradient method causes the generalization performance to deteriorate further due to the lack of regularization capability. We propose an improved second order method by smoothing the loss function, which allows second order methods to generalize as well as mini-batch SGD.
▲クリックすると拡大されます
2018年度学位論文研究 学士論文
帯域幅最適なGPU間AllReduce通信の階層化 (上野 裕一郎)
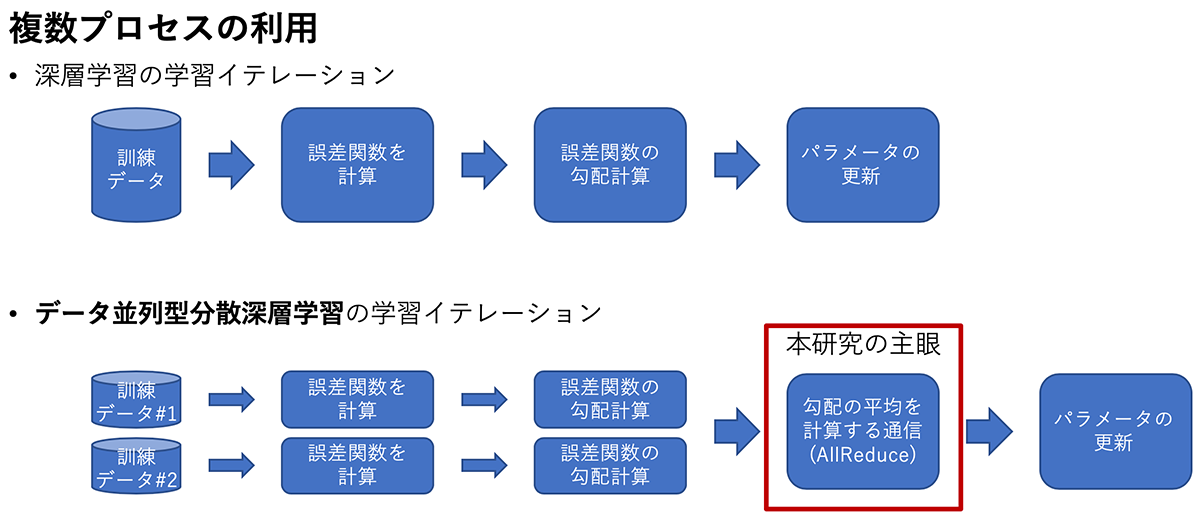
本研究では,データ並列・同期型分散深層学習で,損失関数のパラメータによる勾配の平均値を求めるために用いられるAllReduceと呼ばれる集団通信アルゴリズムに着目した.この通信は,MPI(Message Passing Interface)の集団通信の仕様に含まれているが,分散深層学習で用いられる大きなメッセージサイズの通信は,従来のHPCアプリケーションで使用されてきた通信とは異なり,未だ研究が不十分である.既存研究として,階層化を用いることで通信を改善できることが知られているが,どのような階層化が最適かは十分に調べられていない.本研究では,産総研「ABCIグランドチャレンジ」プログラムにより提供を受けた,AI橋渡しクラウド(ABCI)の計算リソースを用いて,網羅的に階層化通信の性能を評価した.
Yuichiro Ueno and Rio Yokota, "Exhaustive Study of Hierarchical AllReduce Patterns for Large Messages Between GPUs", in IEEE/ACM International Symposium in Cluster, Cloud, and Grid Computing (CCGrid 2019).
▲クリックすると拡大されます
SiameseNetworkによる筆者識別 (郭 林昇)
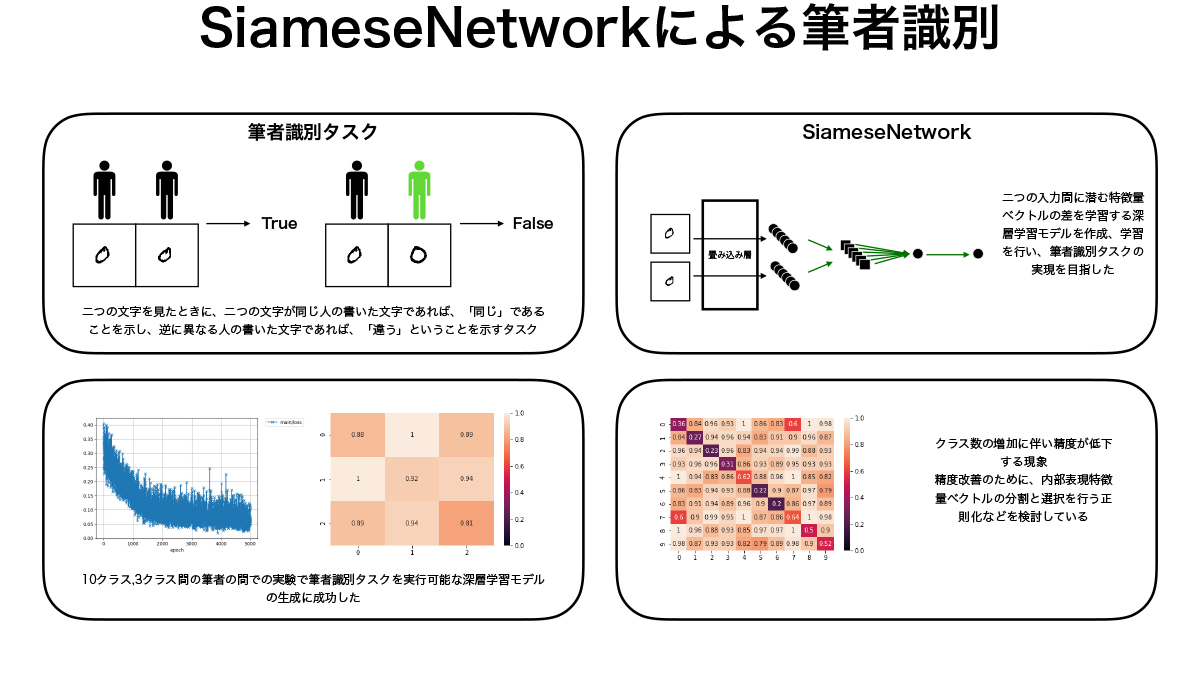
本研究では2入力間の特徴量を学習するSiameseNetworkと呼ばれる深層学習モデルを用いて筆者識別タスクを行うモデルの生成を行なった。NISTデータセットから取り出した筆者ごとの手書き数字を用いてモデルの学習を行い、同じくNISTデータセットから作成したテストデータに対して筆者識別タスクが可能であるモデルの生成に成功した。精度の検証も行なったが、クラス数の少ない場合には高い精度での識別が行えていたが、クラス数が多くなると精度が下がる傾向があり、内部表現の分割等による正則化を行い精度向上を目指すことが今後の課題である。
▲クリックすると拡大されます
自然勾配法に基づくベイズ的深層学習に関する研究 (中田 光)
深層学習における変分事後分布に正規分布を仮定した変分推論では,変分事後分布の共分散行列の大きさがニューラルネットワークのパラメータ数に依存して大きくなるため,計算量やメモリ容量の観点からパラメータ間の相関を考慮した変分事後分布の推定は困難とされてきた.自然勾配法の効率的な近似手法であるK-FACを変分推論における最適化に用いたNoisy K-FACは,大規模なニューラルネットワークにおいても層ごとのパラメータの相関を考慮した変分事後分布の推定を可能とし,学習が汎化することが示されている.本研究ではNoisy K-FACに着目し,既存研究では明らかにされてこなかった、変分パラメータの探索にMCVIを適用した場合の検証を行なった.
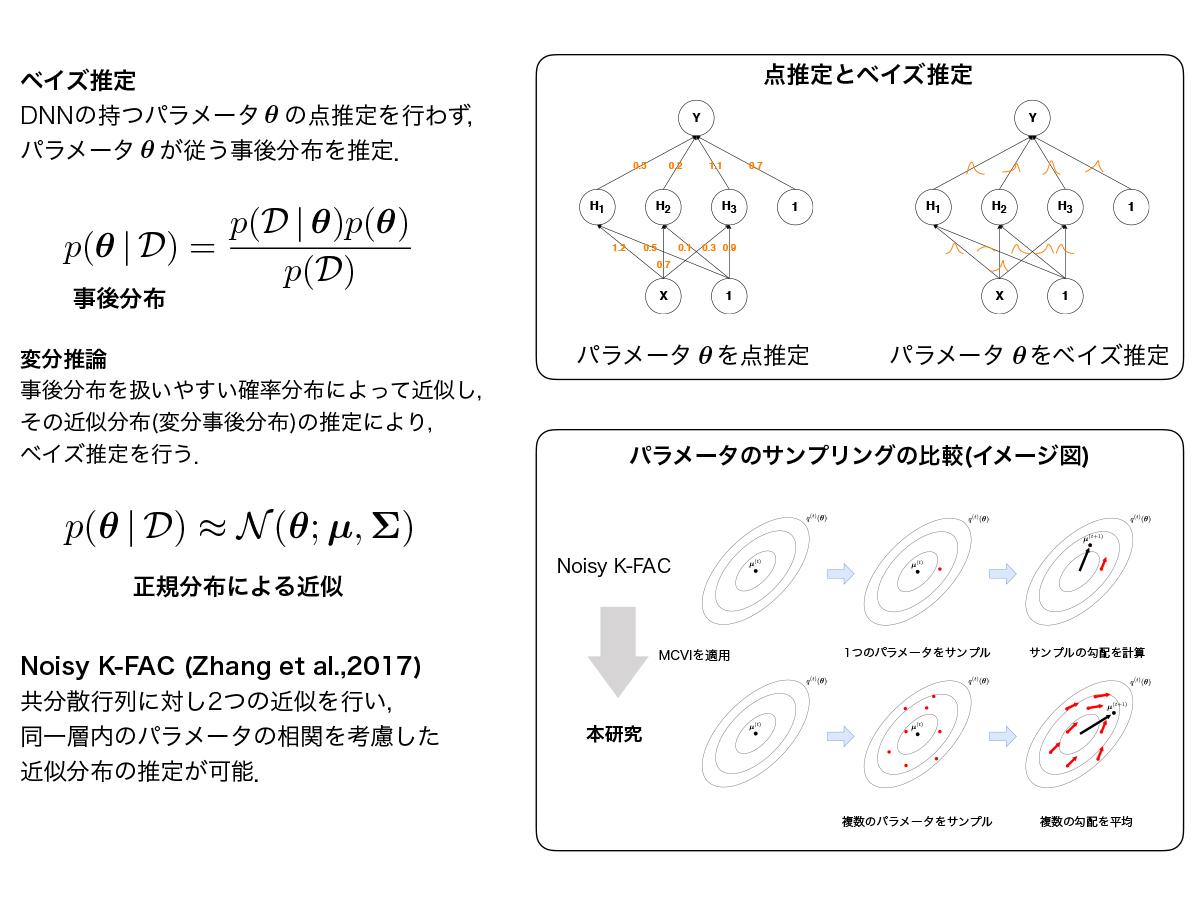
▲クリックすると拡大されます