
横田理央研究室では、全員にラップトップ、ディスプレイ、キーボード、マウスなど一式を支給します。 また、多数のスーパーコンピュータを利用することができます。
例えば:
このほかにも、研究室で運用する「ひなどりクラスタ」があります。
ひなどりクラスタ
ひなどりクラスタはスーパーコンピュータなどでは取り入れられていない最新の環境をいち早く導入して研究を行うことを目的に構築・運用されています。
学生が主体となって仕様決定・調達・運用を行っています。
ハードウェア
横田理央研究室での研究対象はGPUであることが多いため、多数のGPUサーバを保有しています(合計81GPUs)。
CPU |
ホストメモリ |
GPU (1ノードあたりの搭載数) |
台数 |
|---|---|---|---|
AMD Ryzen Threadripper 3960X |
128GB |
NVIDIA RTX A4500 (2) |
4 |
AMD EPYC 7402 |
512GB |
NVIDIA GeForce RTX 3090 (8) |
1 |
NVIDIA GeForce RTX 3090 (6) |
1 |
||
AMD EPYC 7313P |
512GB |
NVIDIA GeForce RTX 3090 (4) |
1 |
AMD EPYC 7313 |
512GB |
NVIDIA A100 80GB PCIe (8) |
1 |
AMD EPYC 7453 |
512GB |
NVIDIA RTX A6000 (6) |
1 |
- |
512GB |
NVIDIA RTX 6000 Ada (8) |
1 |
AMD EPYC 9654 |
384GB |
NVIDIA RTX 6000 Ada (2) |
1 |
Intel Xeon Gold 5418Y |
512GB |
NVIDIA GeForce RTX 4090 (8) |
1 |
NVIDIA GeForce RTX 4090 (7) |
1 |
||
Intel Xeon Gold 6530 |
512GB |
NVIDIA H100 NVL (2) |
1 |
Intel Xeon Platinum 8570 |
2TB |
NVIDIA B200 (8) |
1 |
Intel Xeon Silver 4514Y |
1TB |
NVIDIA RTX PRO 6000 Blackwell (6) |
1 |
AMD EPYC 7502 |
1TB |
-(CPU計算ノード) |
1 |
NFSファイルサーバー 合計500TB以上
(2026.07.05現在)





▲クリックすると拡大されます
ソフトウェア
ジョブスケジューリング
ジョブスケジューリングにはSlurm Workload Managerをベースとし、より簡単にジョブの投入ができる独自のシステムを用いています。
Slurmには1ノードに複数のジョブを割り当てる機能がありますが、これを簡単に利用するための機能が備わっています。
監視基盤
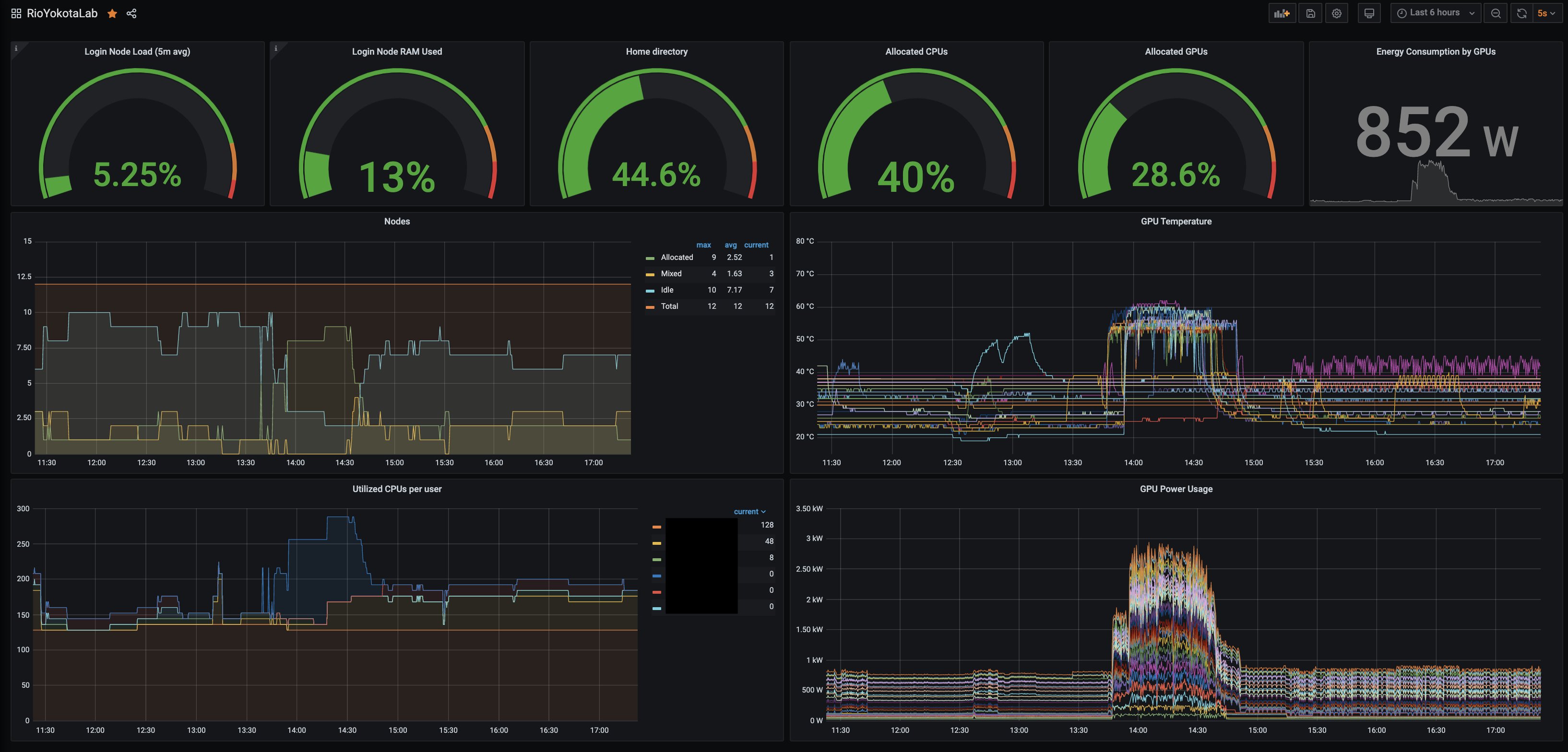
Prometheusによるメトリクスの集約、Grafanaによるメトリクスの可視化を行っています。
監視している主なメトリクスには、CPU使用率やGPU使用率といった性能最適化に利用できるものや、ひなどりクラスタの利用履歴やGPUの温度、消費電力など管理者による監視に必要なものがあります。
ユーザは様々な情報にブラウザ経由でアクセスできます。
開発環境
CUDA関係や各種コンパイラはEnvironment Modulesで管理されており、好きなバージョンを指定して使うことができます。
標準的なアプリケーション以外にも、プログラムの実行中にGPUの温度や消費電力などを記録していく独自のアプリケーションの提供も行っています。
運用
運用の上で「管理に時間をかけない」ことを大切にしています。
クラスタの運用は、学生や先生のボランティアによって行われておりますが、本業の研究が進まなくなってしまっては元も子もありません。
そのため、構成管理ツールのAnsibleや、リモート管理ツールのIPMI、ユーザ管理のためLDAPのSaaSを導入するなどして、できるだけ手が掛からないようにしています。
新たにノードをセットアップする処理も自動化されており、OSのインストールから30分程度でユーザが利用できます。