

2023年度 主な研究テーマ
大規模言語モデル(LLM)の事前学習
横田研では世界最大級のスパコンAurora (63,744 GPU)、Frontier (37,888 GPU)、Fugaku (158,976 CPU)、LUMI (20,480 GPU)、Summit (27,648 GPU)などを用いて大規模な事前学習を行うプロジェクトに参画しています。 この他にも国内のスパコンABCI (5,312 GPU)、TSUBAME (960 GPU)、MDX(320 GPU)などを用いるプロジェクトにも参画しています。LLMの事前学習には膨大な計算資源が必要になるため、このようなスパコンの利用が不可欠となります。自然言語処理側の研究者はそれぞれのプロジェクトで異なるデータを試していますが、共通基盤となるMegatron-DeepSpeed、GPT-NeoXなどのフレームワークをこれらの異なるスパコンで効率的に動作させ、環境構築や大規模学習の安定化に関するノウハウを橋渡しできるグループがいることは非常に重要だと考えます。

▲クリックすると拡大されます
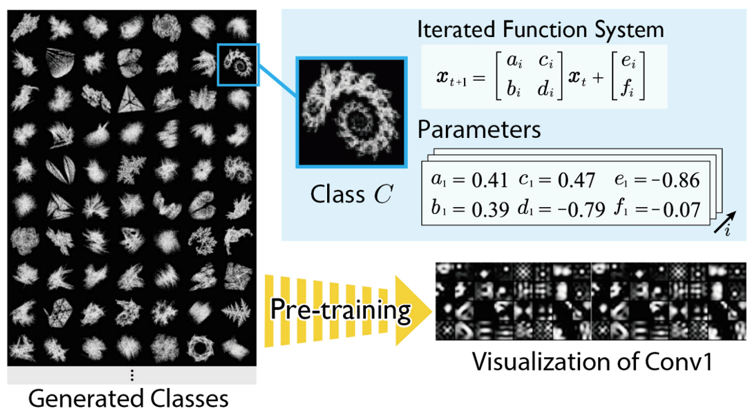
人工画像による大規模画像モデルの事前学習
言語データも著作権やプライバシーなどの問題を抱えていますが、画像データに関しても同様で、現在大規模事前学習に用いられているJFTやLAIONなどの大規模実画像データセットにおいては、法令遵守と共に倫理面も重要課題となっています。しかし、数式から生成されるフラクタル画像などはこのようなリスクは皆無です。これまで、産総研との共同研究において、このような人工画像を用いてもImageNet-21kなどの実画像によるVision Transformerの事前学習と比べて、同等(もしくは優位な)事前学習効果が観測されています。

▲クリックすると拡大されます
ベイズ双対理論を応用した継続学習
現在の深層学習では、大規模な基盤モデルを最新のデータで継続的に学習できる状況にはなっていません。限られた条件下での転移学習やファインチューニングはできていますが、根本的な解決にはいたっていません。ベイズ双対理論を応用することで継続学習の研究を大きく進展させることができる可能性があります。理研AIPとの共同研究では、忘却の起きにくい継続学習について数学的な観点と高性能計算の観点の両方から検討をおこなっています。
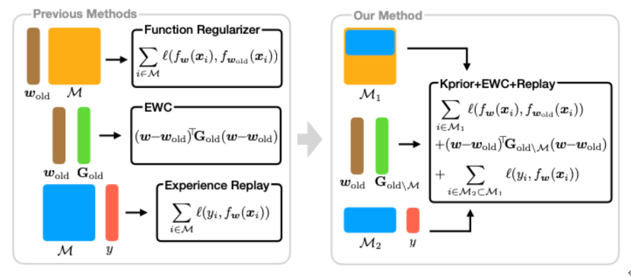
▲クリックすると拡大されます
2022年度 学位論文研究 修士論文
人工画像による事前学習のスケールアップとその効果 (高島 空良)
画像認識タスクの文脈では、JFT-300M/3B のような超大規模な実画像データセットで事前 学習した ViT によって最高精度が更新されている。一方で、事前学習に用いられるラベル付き 実画像データセットは、倫理的・権利的問題や、収集・ラベリングの困難、一部組織による寡 占など、多くの問題を抱えており、データセット大規模化によってこれらの問題を制御することは難しくなっている。そこで本研究では、ViT を事前学習させる FDSL 用人工画像データセットについて、1) 画像 内オブジェクトの輪郭が重要、2) 画像表現のバリエーションが重要、3) スケールアップにより 事前学習効果の向上が可能、という 3 つの仮説を立て、それぞれの仮説を検証できる FDSL 用 データセット{ExFractalDB, RCDB, VisualAtom}を新規に構築し、各データセットがもたらす事前学習効果の比較検証を実施すると共に、FDSL 手法の事前学習効果の底上げを図った。
▲クリックすると拡大されます
Model Reduction Effect of NAS during Finetuning of Vision Transformers (Xinyu Zhang)
Vision Transformers (ViT), an application of Transformer used in natural language processing, have surpassed traditional Convolutional Neural Networks (CNN) in image classification on ImageNet by pre-training on large datasets. However, the models are becoming so large to achieve high accuracy that they cannot even fit on a single GPU, which limits their usefulness during inference. In order to reduce the size of such large ViT models while keeping their performance, we utilize Neural Architecture Search (NAS), which makes it possible to automatically design architectures of deep neural networks. We propose a method called Auto-MetaFormer, which can automatically search for architecture of MetaFormer based on algorithm of DARTS by Liu et al. It uses a gradient based approach to search for architecture by training architecture weights along with model weights. Auto-MetaFormer succeeds in automatically searching the MetaFormer architecture, gaining a 2% increase in accuracy using the same number of parameters. For the same classification accuracy, the number of parameters also be further reduced by 20% compared to the manually designed architecture.
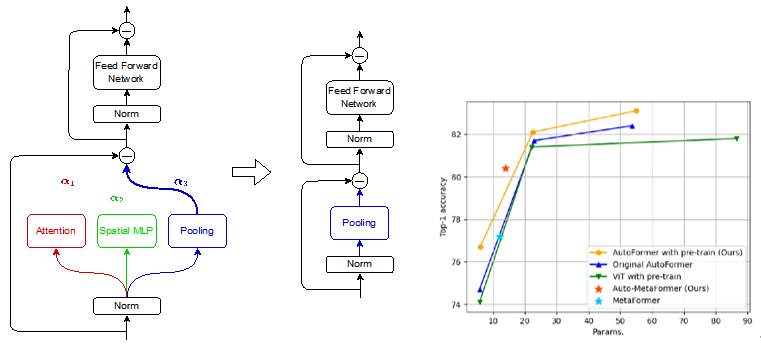
▲クリックすると拡大されます
Neural Network Pruning based on Second-Order Information (Sixue Wang)
Nowadays, deep learning has demonstrated its ability to solve arduous tasks in different domains, such as computer vision, voice interaction, and natural language processing, but there is a huge gap between academia and industry when considering cost, efficiency and quality. Neural network pruning is a common technique to reduce the size of neural networks. It selects some redundant parameters and removes them all. The goal of this thesis is to exploit second-order information in neural network pruning in a practical manner. We demonstrate that second-order neural network pruning can achieve better or comparable results within similar computational resources.
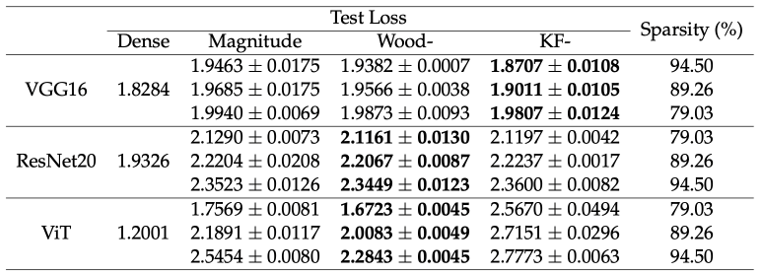
▲クリックすると拡大されます
走行動画の大規模自己教師あり学習 (高橋 那弥)
自動運転において、カメラやライダーから得られた外界の環境の認識は安全を担保するための技術の 中核をなす。これらの認識精度は深層学習の登場により飛躍的に向上したが、完全自動運転を実現する ためにはまだ十分であるとは言えない。その原因の一つとして、自動車の走行データは膨大な数が収集可能である一方で、真値ラベルのアノテーションコストは高く、学習に要する教師データを十分に用意するのは難しいという課題がある。本研究では、画像ピクセル単位での自己教師あり学習を用いた走行動画の事前学習を行い、かつオプ ティカルフローを用いて物体の見えの時間変化に頑健な認識モデルを構築することを目指す。その事前学習効果の評価を行う下流タスクとしては CityScapes を用いたセマンティックセグメンテーションで の評価を行う。その結果、画像ピクセル単位で比較する際の近傍の定義によって、精度が大きく変化することがわかった。また、本来は正例ではないピクセルペアが正例と判定される擬正例をマスクによって除去することで、精度がさらに改善されることがわかった。
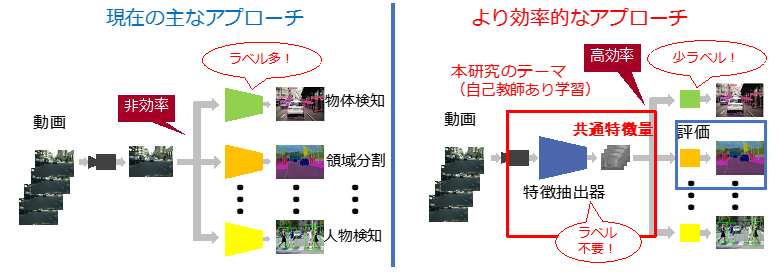
▲クリックすると拡大されます
深層学習を用いた Visual SLAM による 変化検出 (大川 快)
自動運転や AR/MR、ロボティクスにおいて「目」の役割 を果たすのは、連続する画像列等の情報 からカメラの自己位置推定や周辺の 3 次元マップを復元する Visual SLAM であり、AI 社会における 最重要基盤技術の 1 つとなっている。近年、Visual SLAM の研究において自己位置と3次元マップを ロバストにリアルタイムで推定可能な手法が登場している。また近年進化が目覚ましい深層学習を取り入れた手法も提案されており、より高精度な自己位置推定と3次元マップの復元が可能となってき ている。しかし、3次元マップの作成から一定時間が経過すると実際のシーンが変化し、3次元マップとの間に齟齬が生まれる可能性がある。このような齟齬は Visual SLAM の精度を低下させ、古い情報の蓄積による 3 次元マップの肥大化を引き起こす。本研究では DROID-SLAM から得られる情報を用いて2時刻の 3 次元マップに対 して変化検出を行う手法を提案する。DROID-SLAM で推定された密な深度情報と回帰型ニューラル ネットワークで推定される Optical Flow を用いて変化マスクを推定する。また、新たに変化を考慮した目的関数を導入し、変化マスクの最適化を行った。さらに、本研究に適した合成画像データセットを 作成し、実験を行った。実験により、DROID-SLAM で推定された2時刻の 3 次元マップに対して変化 マスクの推定を行うことが可能であることを確認した。
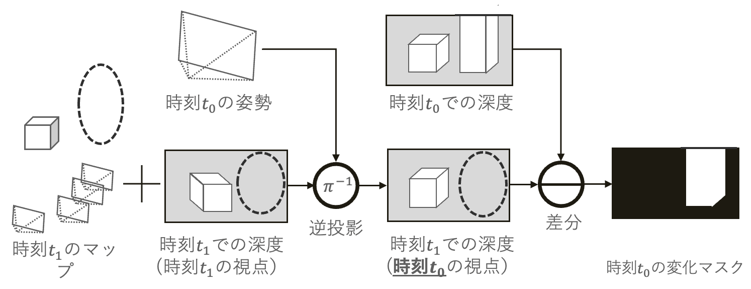
▲クリックすると拡大されます
2022年度 学位論文研究 学士論文
深層学習の二次最適化における勾配の前処理に関する考察 (石川 智貴)
曲率行列 (ヘッセ行列, フィッシャー情報行列,2 次モーメント)による勾配の前処理は深層学習の幅広いタスクにおいて重要な技術となっている。深層学習の最適化を高速化する二次最適化を始め、継続学習、枝刈り、ベイズ推論など様々な領域において勾配の前処理が使われている。深層学習の二次最適化では曲率行列を近似した上で勾配の前処理を行う。その際の近似アルゴリズムとして 様々な種類のものが提案されているが、その特性の違いについてはほとんど調べられていない。そこで、本研究ではメモリ消費量や計算量などの計算的側面と学習の収束性の 2 つの観点からこれらのアルゴリズムを比較する。全体の学習時間は 1step あたりの計算時間と収束にかかるステップ数の積に よって決まるため、この2つの特性の両方を調べることがとても重要である。その結果、KFAC や Shampoo などの多くの二次最適化手法においては、ラージバッチサイズでの学習でとりわけ活躍す る可能性があることがわかった。また、SENG や SMW-NG などの逆行列計算に SMW 公式を利用する二次最適化手法は他の手法とは異なる性質を持つことが分かった。
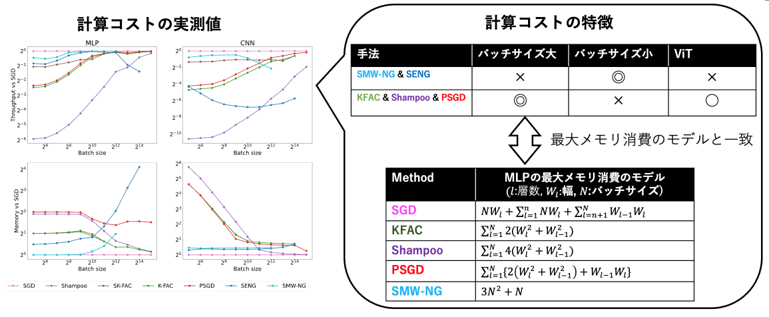
▲クリックすると拡大されます
Newton Fractal を用いた Vision Transformer の事前学習 (近江 俊樹)
画像認識分野では、JFT-300M/3B などの大規模自然画像データセットを用いて事前学習を行った後に、目的のタスクのデータでファインチューニングする手法が主流になっている。事前学習に用 いるデータセットが大規模であるほど高い画像分類性能や物体認識性能が得られることが知られており、どのデータセットを事前学習に用いるかは重要な問題になっている。しかしながら、自然画像 データセットは、大量の画像の収集、ラベリングコスト、著作権の問題、内容の偏りの問題、公平性 や不快なラベルの問題など、多くの問題を抱えている。本研究では、ニュートン法により生成されるニュートンフラクタル画像で構成された画像データ セットを用いて Vision Transformer の Tiny モデルの事前学習を行い、CIFAR-10/100 のファイン チューニングタスクの精度によるデータセットの性能の評価を行った。さらに、従来手法のデータ セットである FractalDB、ExFractalDB と自然画像データセットの ImageNet でも同様の実験を行 うことで、従来手法との比較をした。結果として、ニュートンフラクタル画像のデータセットによる 事前学習効果が確認され、従来の FDSL データセットと同様に、カラー画像やグレースケール画像 よりも白黒画像により構成されたデータセットの性能が高く、画像の生成条件を変えることで性能が 向上することが分かった。ImageNet よりも事前学習効果は低い結果となったが、従来の FDSL 手法で用いられる画像表現に比べて高い事前学習効果が確認された。

▲クリックすると拡大されます
量子渦計算の高速多重極展開法を用いた高速化 (齋藤 智和)
極低温の流体は量子的な効果により粘性が 0 になる。そのような流体は超流体と呼ばれる。超流体の物理的な性質は工学的に重要であるが、応用のためには超流体の乱流化などの複雑な現象を解明する必要がある。しかし、超流体を実験する場合、流体を極低温に維持する必要があるため高額な設備が必要となる。そこで、シミュレーションによる解明が重要になるが、乱流のシミュレーションを行う場合、有限要素法などの格子を必要とする方法は格子を非常に細かくする必要があり、膨大な時間 がかかる。そこで、量子乱流は多数の渦糸からなる非粘性流体であり渦糸近似法を利用するのが有効である。本研究では、Biot-Savart の法則に基づく渦粒子間の相互作用を計算する FMM を CPU 上及び GPU 上で実装し、その計算速度と精度について評価を行った。FMM は近似アルゴリズムでありその精度は多重極展開の次数 P に依存するが、実装においても P の増加 とともに誤差が減少することを確認できた。さらに、FMM では周期境界条件を高速に計算可能であるが、粒子数が 104 個、FMM の次数が P = 10 の場合に周期鏡像が 274 個の付近で誤差が一定の値 に収束することが確認できた。

▲クリックすると拡大されます
2021年度 学位論文研究 修士論文
確率的重み平均化法のラージバッチ問題及び分布外汎化への拡張 (所畑 貴大)
深層ニューラルネットワークモデルの実社会への適用への課題は,学習時間の増加や分布外のデータに対する汎化能力の低下など数多く存在する。学習時間の増加問題は,学習の高速化手法として複数の計算機を並列に用いて学習を行う分散並列深層学習が存在するが,汎化性能が低下する問題が経験的に知られている。本研究は,Stochastic Weight Averaging(SWA)に注目し,分散並列深層学習における汎化性能の低下問題と分布外のデータに対する汎化の改善を目的とする。SWAは,学習中に異なる局所解に収束した複数のモデルを得て平均化することで,一種のアンサンブル学習の近似を行う学習手法である。本研究ではSWAのハイパーパラメータへの依存性を網羅的に調査した。そして,SWAをを分散並列深層学習に適用し汎化性能を改善できることを示した。更に,分布外のデータに対する汎化タスクにおけるSWAの有効性を検証し,改善手法の提案を行なった。
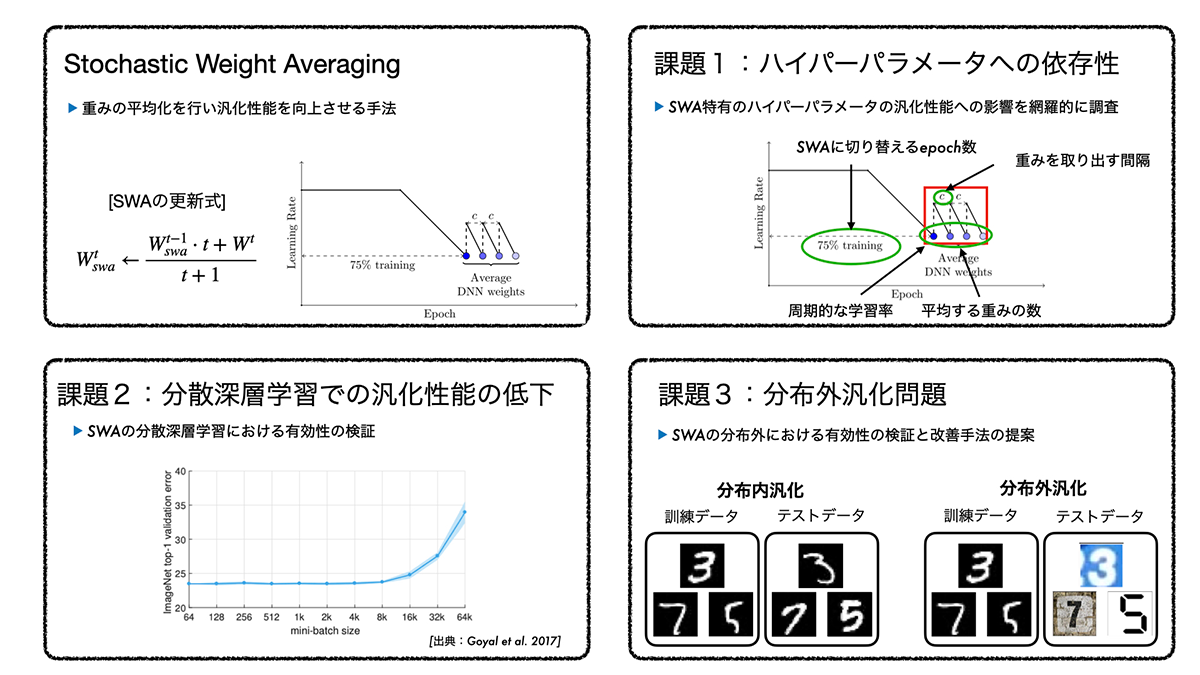
▲クリックすると拡大されます
Off-Policy Inverse Reinforcement Learning via Distribution Matching (星野 華)
Inverse Reinforcement Learning (IRL) is attractive in scenarios where reward engineering can be tedious. However, prior IRL algorithms use on-policy transitions, which require intensive sampling from the current policy for stable and optimal performance. This limits IRL applications in the real world, where environment interactions can become highly expensive. To tackle this problem, we present Off-Policy Inverse Reinforcement Learning (OPIRL), which (1) adopts off-policy data distribution instead of on-policy and enables significant reduction of the number of interactions with the environment, (2) learns a reward function that is transferable with high generalization capabilities on changing dynamics, and (3) leverages mode-covering behavior for faster convergence. We demonstrate that our method is considerably more sample efficient and generalizes to novel environments through the experiments. Our method achieves better or comparable results on policy performance baselines with significantly fewer interactions. Furthermore, we empirically show that the recovered reward function generalizes to different tasks where prior arts are prone to fail.
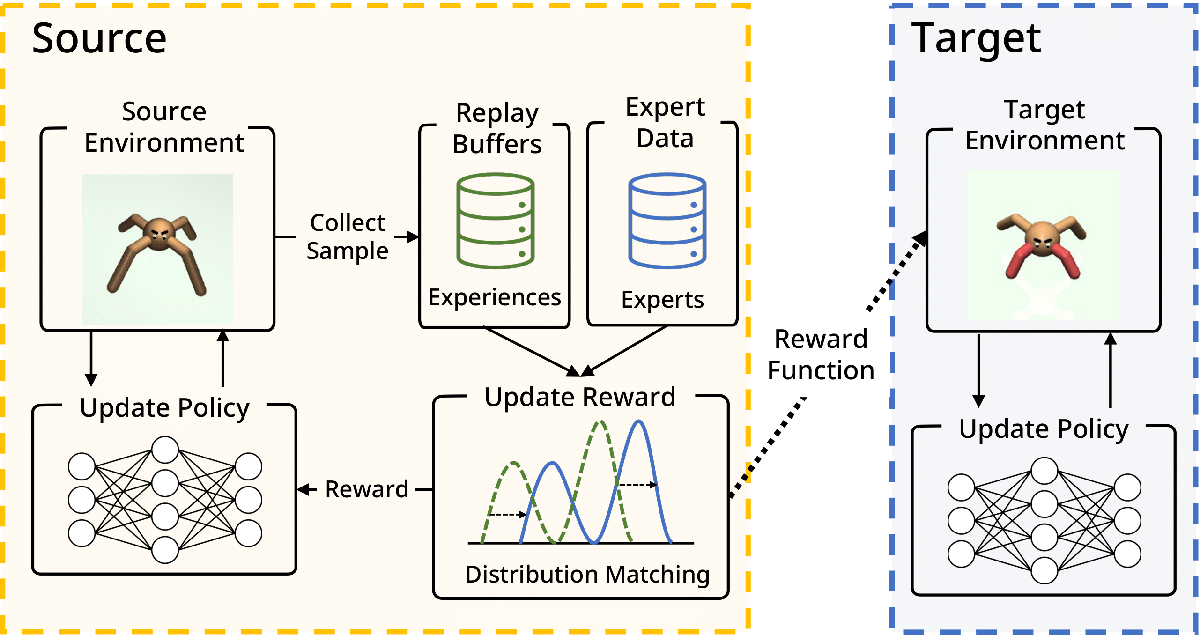
▲クリックすると拡大されます
Informative Sample-Aware Proxy for Deep Metric Learning (Aoyu Li)
Metric Learning is one if the core fundamental tasks of machine learning. In deep metric learning (DML), the proxy-based methods are drawing more and more attention recently because of their flexibility and efficiency while maintaining higher performance. In this work, we propose a novel proxy-based method combined with class-dependent dynamic weighting, called Informative Sample-Aware Proxy (Proxy-ISA).
Proxies, which are class-representative points in the representation space, receive updates based on proxy-sample similarities as sample representations do. In existing methods, it may be possible that a relatively small number of samples producing large gradient magnitudes (i.e., hard samples) and a relatively large number of samples producing small gradient magnitudes (i.e., easy samples) play a major part in the update. Based on the assumption that acquiring too much sensitivities to such extreme sets of samples would deteriorate the generalization ability, the proposed Proxy-ISA directly modifies a gradient weighting factor to each sample. In this work, we first design a method to estimate the learned class-related region to acquire the information of class hardness. By defining the hard and easy samples adaptively to the class hardness, each proxy identifies its own hard and easy samples and reduces their weighting factors with a scheduled threshold function, so that the model acquires more sensitivity to the intermediate samples, which is called "informative" samples. Furthermore, we incorporate the idea of active learning to emphasize the informative samples dynamically according to the learning step, and the dynamic weights are assigned separately for positive pairs and negative pairs. Extensive experiments on the CUB-200-2011, Cars-196, Stanford Online Products and In-shop Clothes Retrieval datasets demonstrate superiority of Proxy-ISA over the state-of-the-art methods.
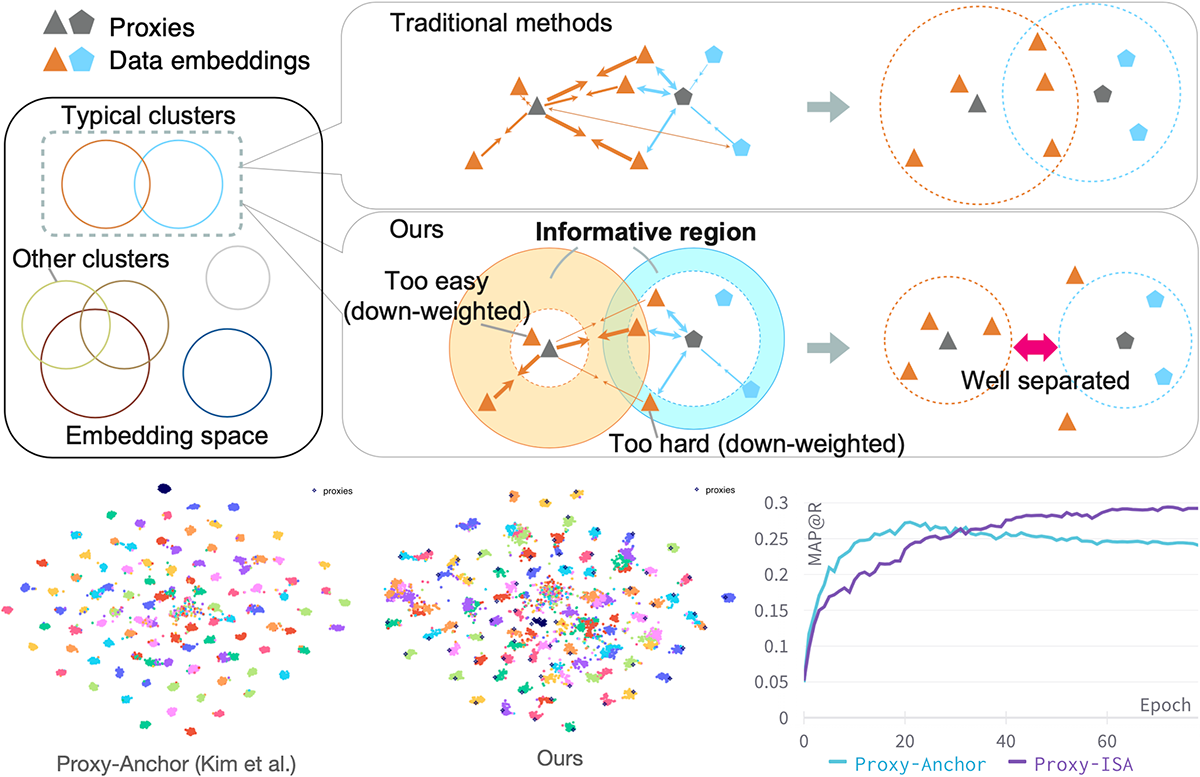
▲クリックすると拡大されます
2021年度 学位論文研究 学士論文
深層学習における情報行列の固有値の高速解法 (石井 央)
深層学習においてフィッシャー情報行列とヘッセ行列は,損失関数の形状の把握やニューラルネットワークモデルの汎化性能の評価,最適化手法への適用といった場面で重要な役割を果たす.ただ,大規模なモデルではこれらの行列を計算することは困難であるため,固有値による評価が行われる.本研究では,データセットやネットワークのアーキテクチャを変えながら,正確なフィッシャー情報行列や高速近似計算で求めたフィッシャー情報行列の固有値密度をStochastic Lanczos Quadrature(SLQ)という手法を用いて近似計算し,正確な固有値から求めた固有値密度と比較した.また,SLQにおける反復回数を変えながら近似精度の関係を調べた.結果として,どのデータセットやアーキテクチャ,行列の近似手法においても,反復回数が5回あればSLQにより求まる固有値の範囲は実際の固有値の範囲とほぼ等しくなり,10回あればSLQにより求めた固有値密度の形は,正確な固有値から求めた固有値密度の形を反映していることが分かった.
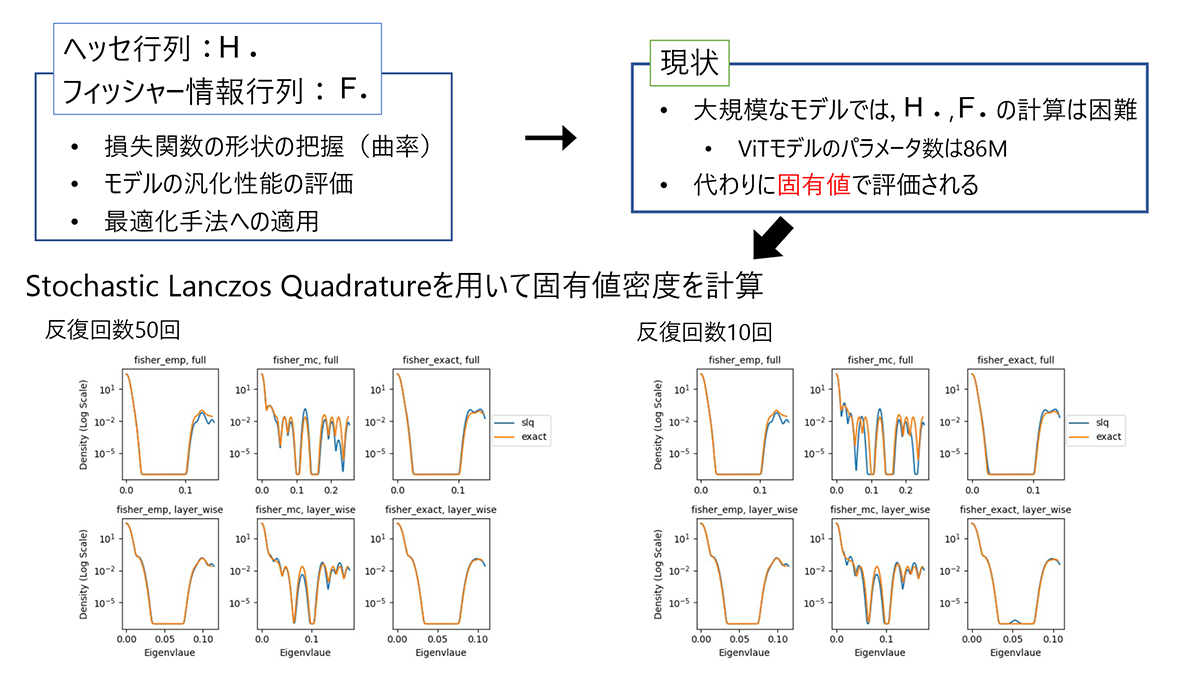
▲クリックすると拡大されます
Vision Transformerにおけるバッチサイズの汎化性能への影響 (中村 秋海)
深層ニューラルネットワークを用いた深層学習は画像分類の様々なベンチマークにおいて,最も良い性能を達成している.画像分類において,事前学習で用いるデータセットは大規模なほどファインチューニング時の性能が良くなるため,膨大な学習時間が必要となる.深層学習は,ミニバッチを用いて勾配を計算し,最適化アルゴリズムを用いて損失関数を段階的に減少させる方法が存在する.バッチサイズを大きくすることで,同期データ並列学習を用いると,バッチサイズが大きいほどプロセス数を上昇させられ,プロセス数が大きいほど処理速度が上昇させられる点である.しかし,バッチサイズを大きくし過ぎると,汎化性能が低下するラージバッチ問題が生じ汎化性能が低下する.バッチサイズの汎化性能への影響の調査し,得られる汎化性能と計算速度を事前に把握することは,効率的なデータ並列学習を行うために必要不可欠である.画像分類における既存の研究では畳み込みに基づくニューラルネットワークにおけるバッチサイズの汎化性能への影響は調べられているが,注意機構に基づくVision Transformerは調べられていない.本論文では,Vision Transformer(ViT)におけるファインチューニング時のバッチサイズと汎化性能への影響を調査した.
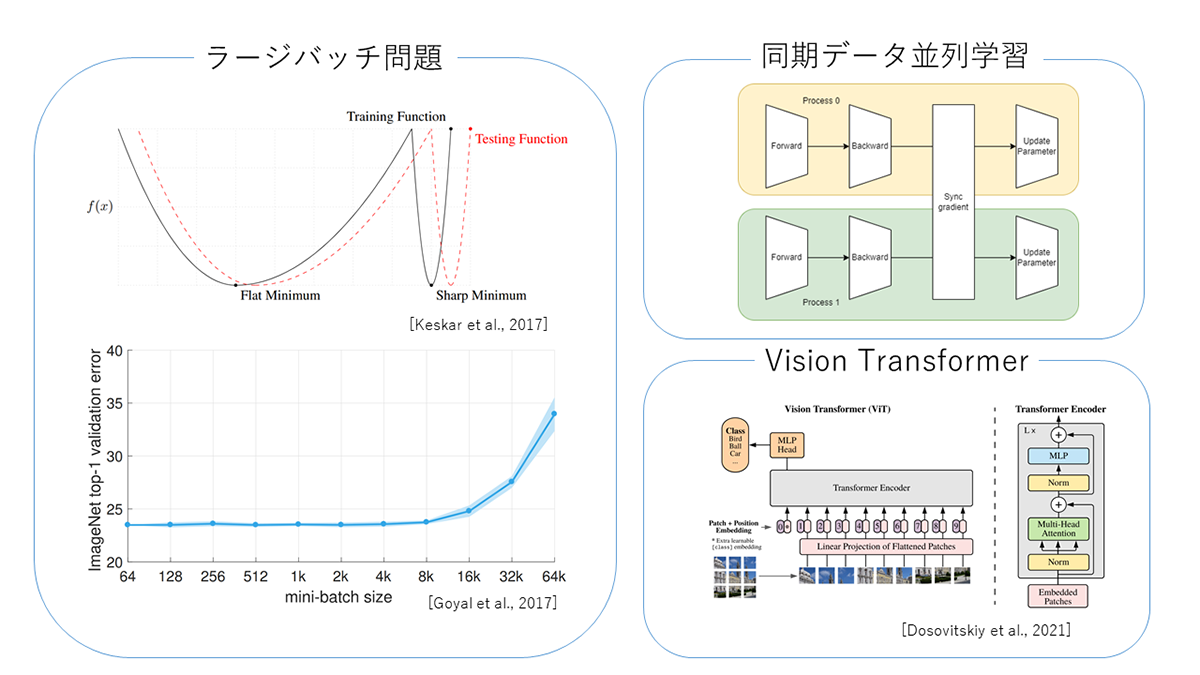
▲クリックすると拡大されます
On the generalization gap of SAM optimizers for very large batch sizes (Elvin Munoz)
The generalization properties of a trained network are highly tied to the geometrical shape of the loss function evaluated at the parameters of the model; it has been found that flat minima increase the generalization properties of a neural network. Due to the stochasticity of most optimizers such as SGD, normally a flat minima will be found rather than a sharp minima. However, as we increase the batch size and thus reduce the stochasticity of the training process, it becomes more likely to fall into a sharp minima. There have been many methods that have been devised to counteract this effect and obtain high generalization properties even when using large batches, one of such methods is SAM (Sharpness-aware minimization). This method has been proven to improve the generalization properties of trained neural networks in the small-mid range of batch sizes and even it has been found to work in distributed training. However, a more in-detail study of its capabilities at higher batch sizes is needed; moreover this method introduces a new hyperparameter (neighborhood size) that needs to be tuned. The main goal of this work was to shed some light at the behavior of this optimizer when using a large batch (reaching almost full batch) and a study of the behavior of the neighborhood size for proper tuning.
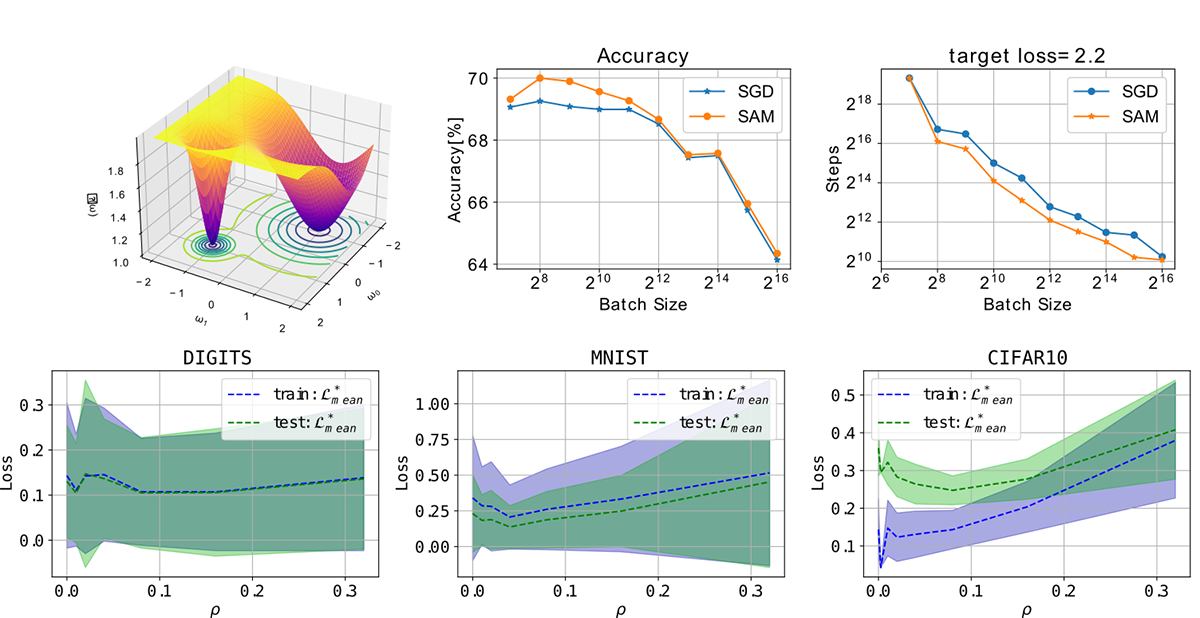
▲クリックすると拡大されます
2020年度 学位論文研究 博士論文
Second-order Optimization for Large-scale Deep Learning(大沢 和樹)
Large-scale distributed training of deep neural networks results in models with worse generalization performance as a result of the increase in the effective mini-batch size. Previous approaches attempt to address this problem by varying the learning rate and batch size over epochs and layers, or ad hoc modifications of Batch Normalization. We propose Scalable and Practical Natural Gradient Descent , a principled approach for training models that allows them to attain similar generalization performance to models trained with first-order optimization methods, but with accelerated convergence. Furthermore, SP-NGD scales to large mini-batch sizes with a negligible computational overhead as compared to first-order methods. We evaluate SP-NGD on a benchmark task where highly optimized first-order methods are available as references: training a ResNet-50 model for image classification on the ImageNet dataset. We demonstrate convergence to a top-1 validation accuracy of 75.4% in 5.5 minutes using a mini-batch size of 32,768 with 1,024 GPUs, as well as an accuracy of 74.9% with an extremely large mini-batch size of 131,072 in 873 steps of SP-NGD.
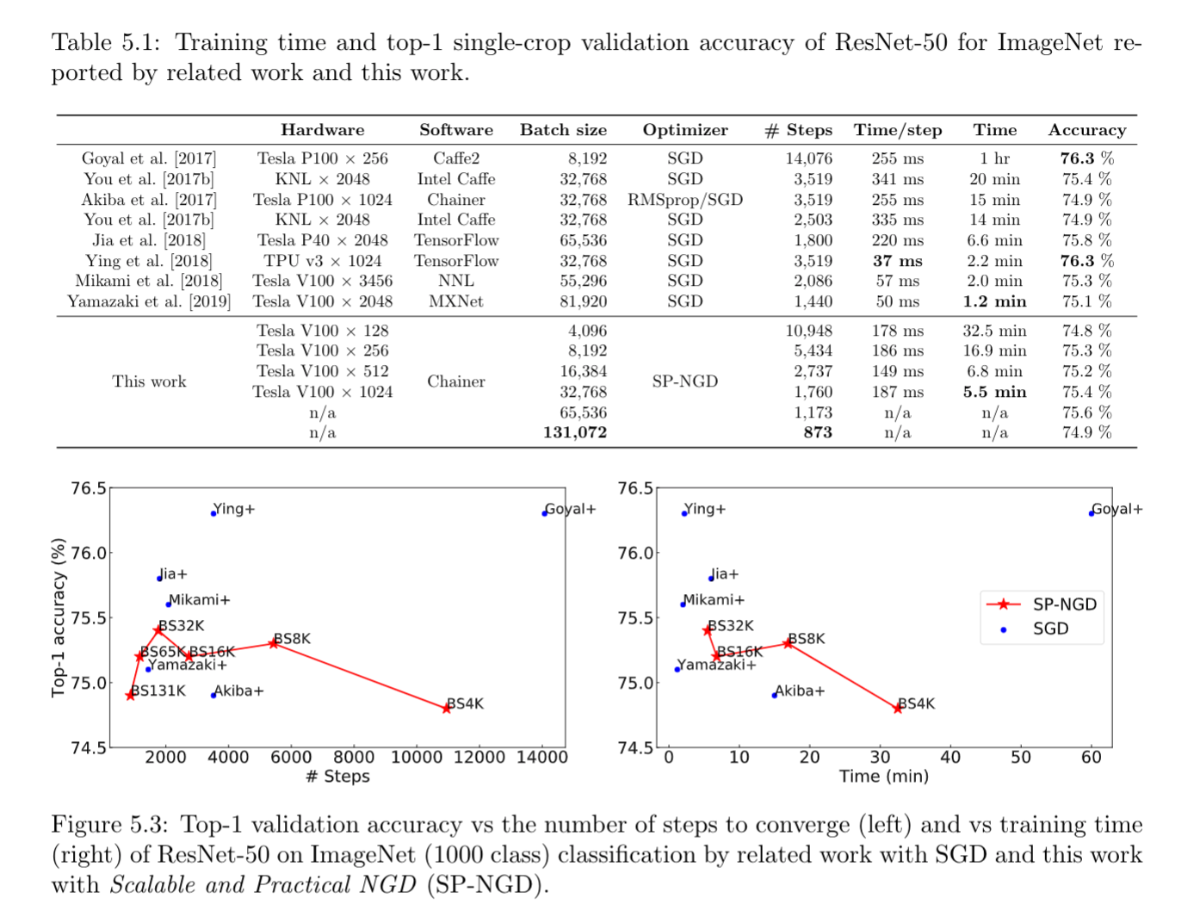
▲クリックすると拡大されます
2020年度 学位論文研究 修士論文
分散深層学習の省メモリ・省I/O化と二次最適化の高速化(上野 裕一郎)
本研究は巨大なDNNを膨大なデータセットで学習する際の種々の問題(学習時間,メモリ使用量,I/O)の解決を目指す. まず,少ない反復数での収束が期待される二次最適化に現れる行列計算の高速化手法を提案し,情報行列を計算しつつ一次最適化と同程度かより速い時間での収束を実現する. さらに,複数ノードとメモリ階層性を用いたメモリ分散手法を提案して,1GPUのメモリに格納できない巨大なDNNの1GPUでの学習と,そうではないDNNについても高速化を実現する. 加えて,ローカルディスクに格納できない膨大なデータセットをランダムに抽出する際にI/Oコストの低いデータ読み込み手法を提案する.
Yuichiro Ueno, Kazuki Osawa, Yohei Tsuji, Akira Naruse, Rio Yokota, Rich Information is Affordable: A Systematic Performance Analysis of Second-order Optimization Using K-FAC, Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Aug. 2020.
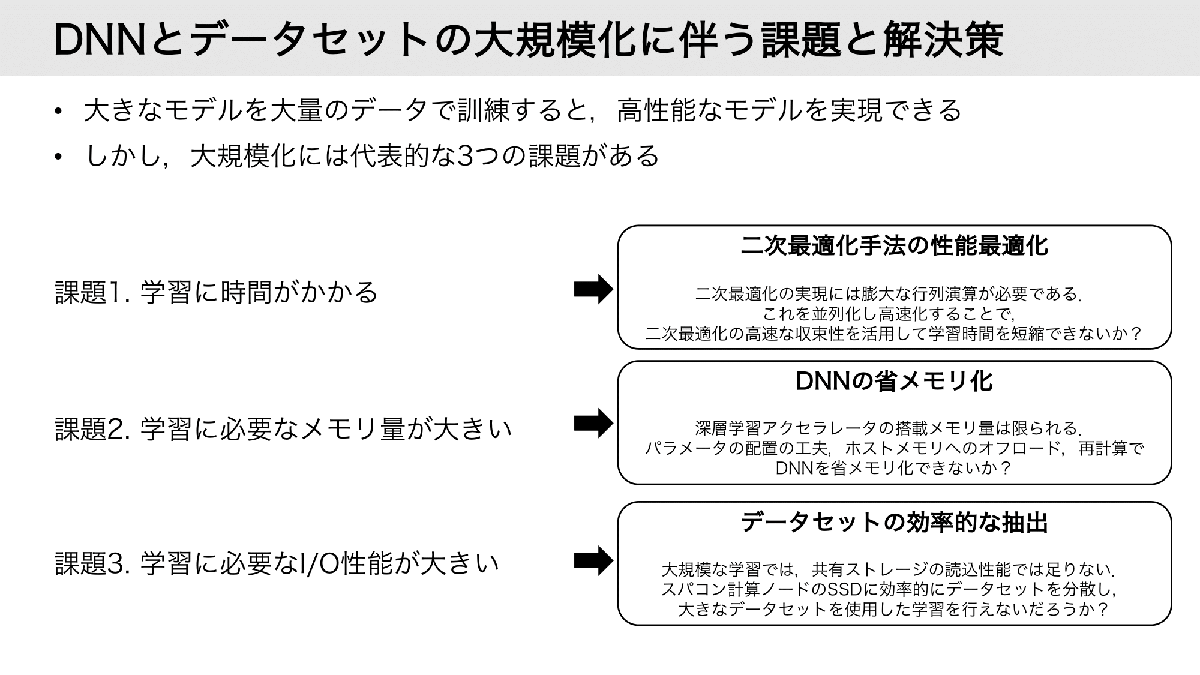
▲クリックすると拡大されます
自己教師あり学習による画像分類のための継続的な事前学習(中田 光)
深層学習では新しく得られたデータでモデルを学習した場合,過去に学習したデータに対する精度が大幅に劣化してしまうことが知られている.この問題は致命的忘却と呼ばれ,継続学習ではこの致命的忘却を防ぐことを目指す.継続学習に関する近年の研究では,多くの場合,常に教師ラベル付きのサンプルが十分に与えられる問題を対象としている.しかし,実問題ではしばしばラベル無しデータや少量のサンプルのみラベル付けされたデータから学習することが求められ,このようなラベルが不足する条件を対象とした継続学習に関する研究は十分に行われていない.そこで本研究では,ラベル付きサンプルが無い場合や不足する場合でも大規模に学習可能な,対照学習による自己教師あり学習に着目し,継続的に自己教師あり学習を行なった場合の検証を行なった.致命的忘却を防ぐため,本研究では蒸留および部分的な過去のデータの再学習を導入し,それらの効果をImageNetを用いて大規模な問題設定で調査した.
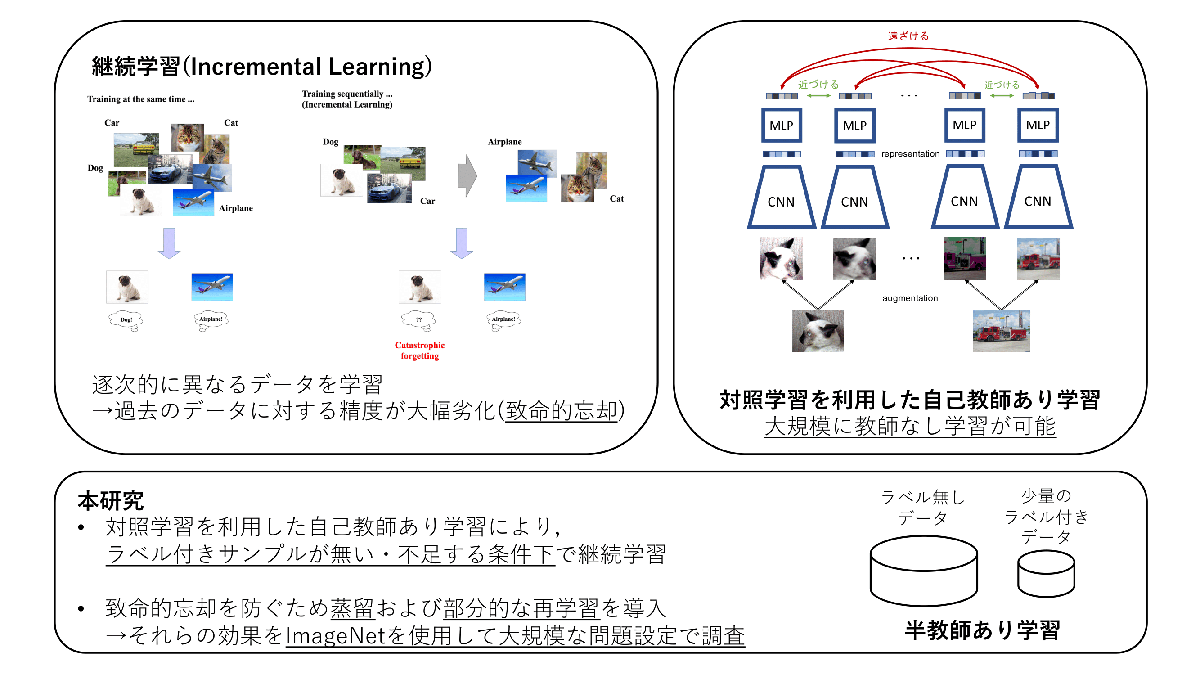
▲クリックすると拡大されます
一貫性損失を利用した Zero-shot 文字認識器 の性能向上(郭 林昇)
文字種の多い言語における手書き文字認識は、文字種の多さに起因するデータセット収集の難しさが課題となっている。Bengali.AI Handwritten Grapheme Classification Challengeでは、この課題に対して、Zero-shotな推論を可能とする文字認識モデルの作成を求められた。本研究では、推論ラベル文字情報から生成したフォント画像を認識する教師あり学習モデルと手書き画像をフォント画像に変換するモデルを作成し、これら、二つを結合することで、Zero-shotな推論を可能にした。提案した手法は、従来手法で用いられていた文字構造の細分化を行いマルチラベリング化してZero-shotな推論を行う手法と比較して、推論精度を60.1%から84.4%に引き上げた。また、本手法の実装にあたり、文字構造の知識は不要であり、検証を行ったベンガル語以外の言語への転用を可能としている。本手法と通常のクラス分類モデルなどを組み合わせた推論パイプラインはKaggleのResearch Code Competitionにおいて、1位の成績を獲得した。
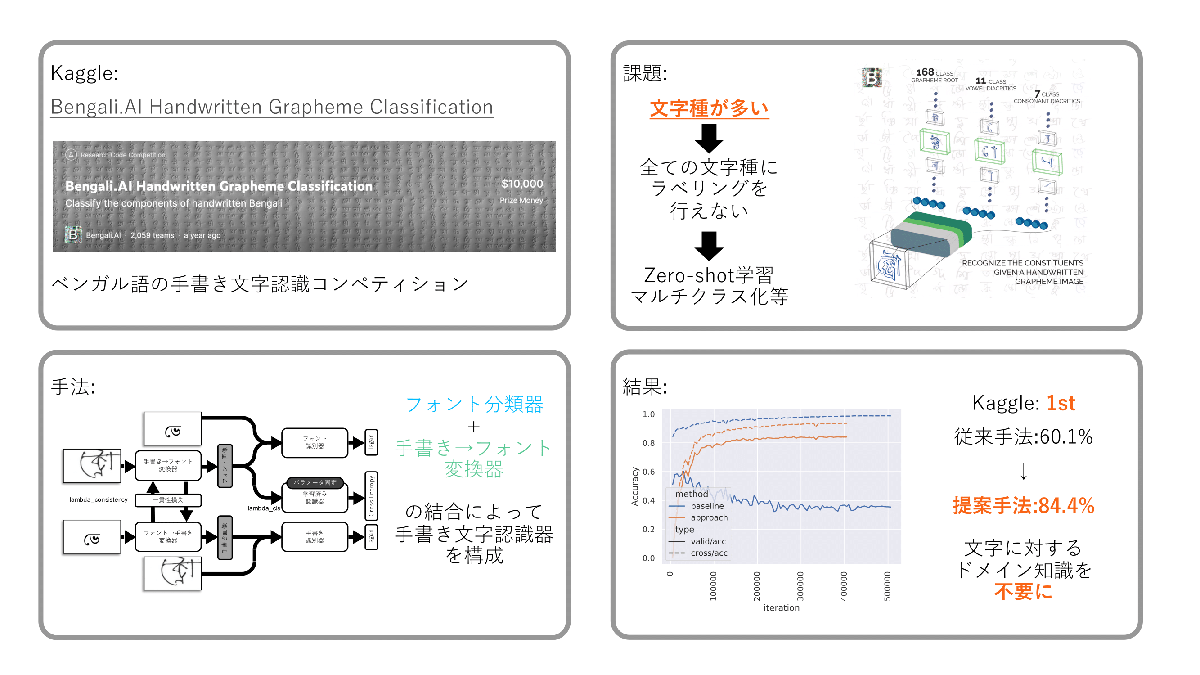
▲クリックすると拡大されます
2020年度 学位論文研究 学士論文
大規模データセット・モデルを用いた深層学習における汎化性能向上手法の有効性について(伊藤 巧)
過学習は深層ニューラルネットワーク(DNN)の課題の一つであり、これを防ぐための正則化手法が提案されている。本研究では2020年にIshidaらによって提案された『Flooding』と呼ばれる、タスクに特化せず、多くの深層学習アルゴリズムに汎用的に導入可能な正則化手法に注目した。Floodingは既存の学習プログラムへの実装も非常に容易であることから今後より広い領域のタスクにおいて活用できることが期待されている。本研究ではIshidaらの実験にはなかった分散深層学習を用いた大規模な問題設定におけるFloodingの効果を検証した。具体的には大規模画像データセットImageNetの分類タスクにおける学習を行った。
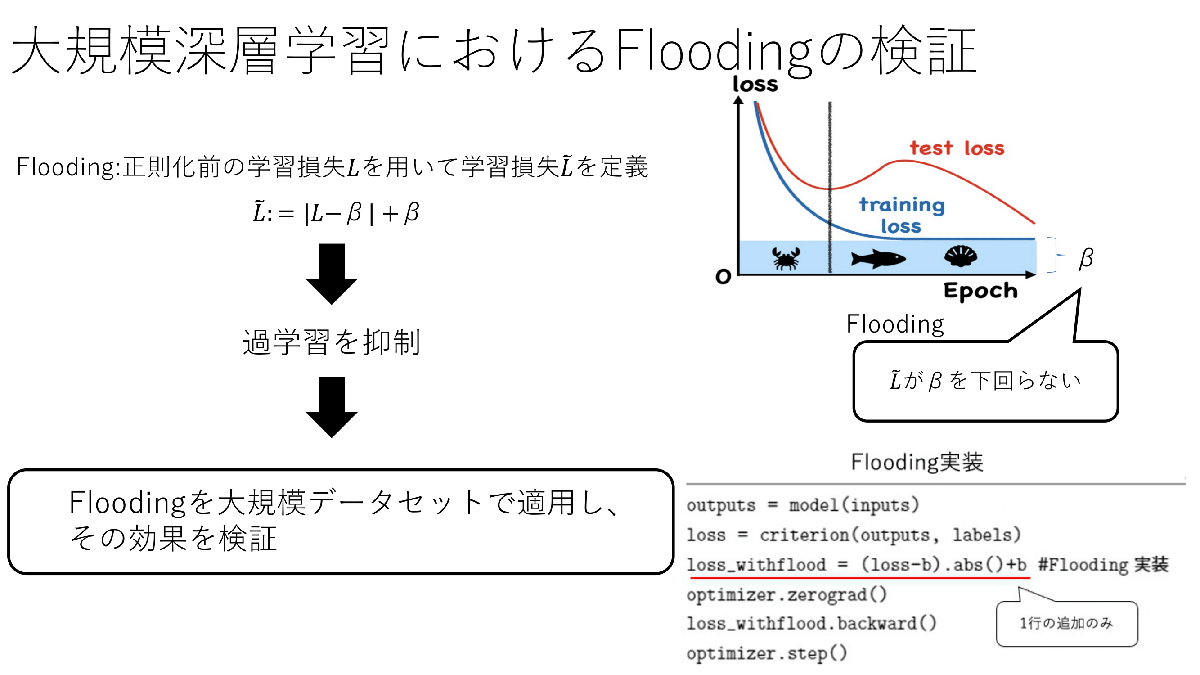
▲クリックすると拡大されます
大規模な事前学習モデルにおけるラージバッチ問題の検証(Xinyu Zhang)
近年,大規模言語モデルの事前学習に多くの注目が集まっている.事前学習には膨大な計算時間を要するため,高速化が重要である.分散深層学習によるラージバッチ学習は,高速化を実現できるが,予測性能が劣化する問題(ラージバッチ問題)が知られている.本研究では,代表的な大規模言語モデルであるBERTの事前学習におけるラージバッチ問題の検証を行った.具体的には,事前学習中の損失の推移,及び言語理解タスクへのファインチューニング後の性能,の二点における変化を観察し評価を行った.
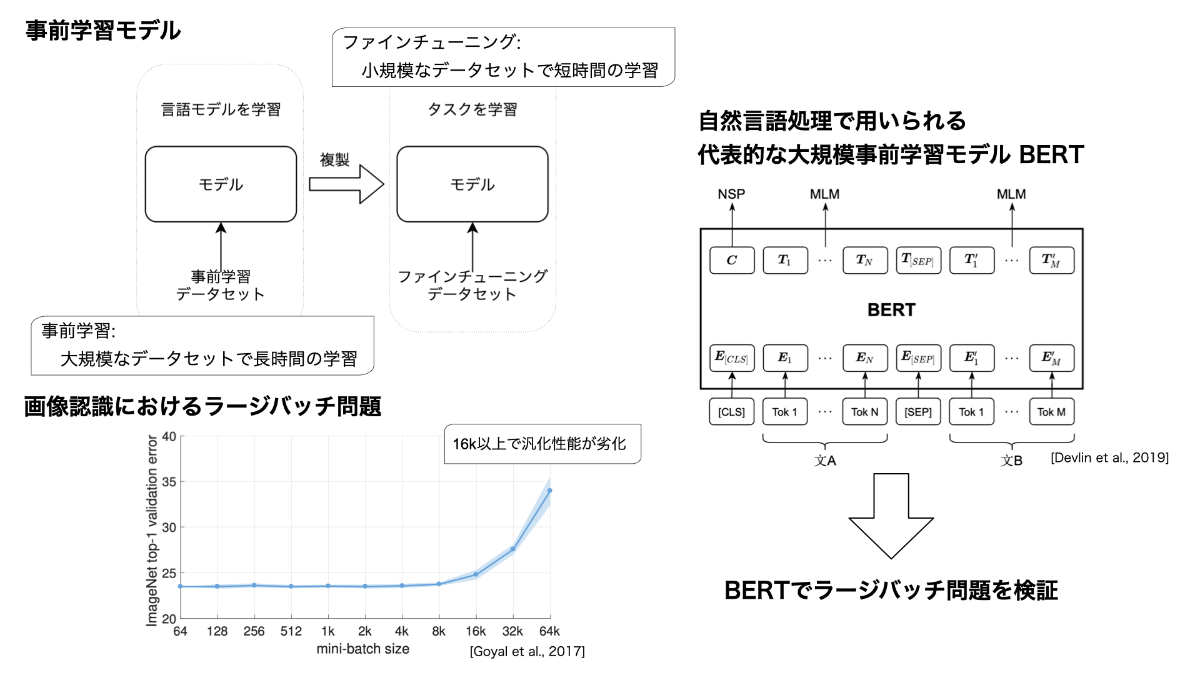
▲クリックすると拡大されます
平坦な解を目指すミニマックス最適化の分散深層学習への応用とその効果(高島 空良)
深層学習の汎化の原理解明を目指した最近の研究では,学習で求まった解近傍における損失関数の曲率(loss sharpness)が汎化に相関がある有力な指標として挙げられている.loss sharpnessを明示的に抑制しflat-minimaを目指す学習アルゴリズムとしてSharpness-Aware Minimization(SAM)が提案された.SAMでは,ミニバッチを複数プロセスに分割して各プロセスが独立にミニマックス最適化を行うことで学習精度が更に向上することが,特定のミニバッチサイズにおいて報告されている.本研究では,分割数やミニバッチサイズを網羅的に変えて畳み込みニューラルネットワークの学習を行い,SAMによる汎化性能向上の効果を検証した.
![]()
▲クリックすると拡大されます
2019年度 学位論文研究 修士論文
Tensorコアを用いたRandomized SVDの実装と評価 (大友 広幸)
本研究ではTensorコアを用いた高速かつ省メモリなRandomized SVDを開発しその評価を行った.
はじめにTensorコアを用いるためのAPIの構造の解析を行い,高速かつ省メモリにTensorコアを用いるためのAPI拡張の開発を行った. つぎにこれを用いてTensorコアを用いたTSQRの開発を行い,その計算精度と計算性能の調査を行った. 実装したTSQRでは入力行列の列数に制限があるため,これを複数回用いることで任意の大きさのQR分解を行うBlockQRを実装しRandomized SVDへの適用を行った. BlockQRではNVIDIAが開発している既存実装と比較し最大99.8%のメモリ消費を削減でき,4倍以上の計算速度の向上が確認された. Randomized SVDではNVIDIAが開発している既存手法での実装に対し精度の劣化を抑えつつ省メモリかつ高速に計算可能であることが確認された.
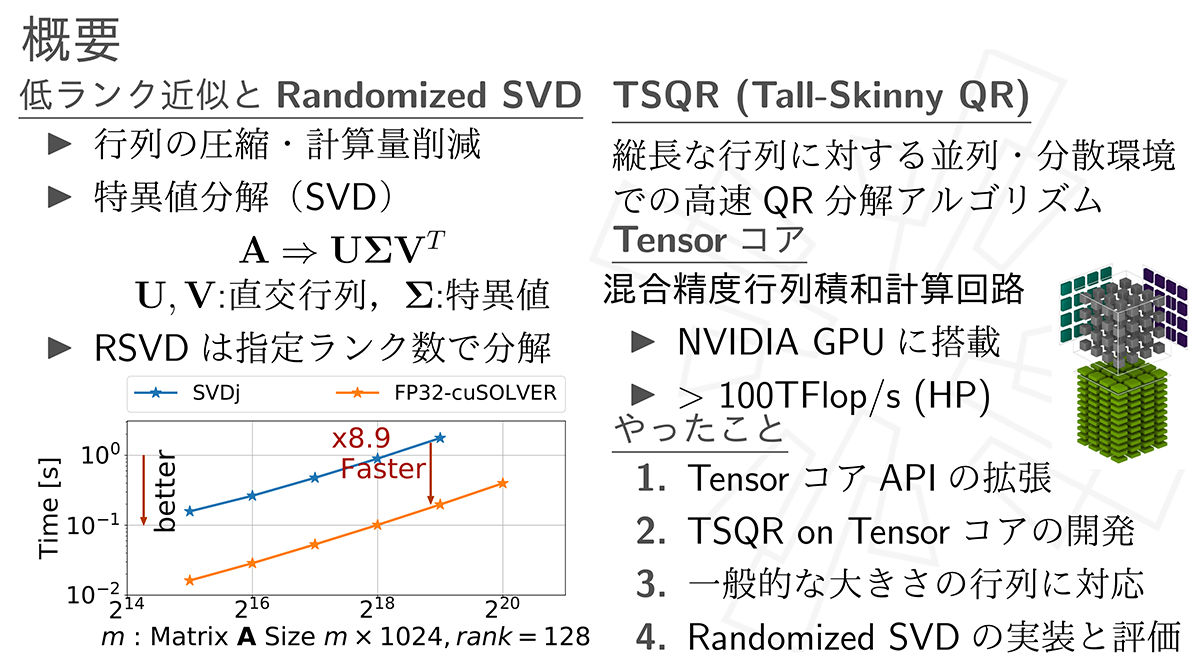
▲クリックすると拡大されます
強化学習における好奇心駆動探索手法の高速なGPU 実装 (桑村 裕二)
強化学習は環境とエージェントの相互応答の繰り返しによって学習を行う機械学習の手法の一つだが、学習に膨大な時間がかかることが知られている。CuLEは代表的なプラットフォームであるAtari emulatorをGPU上で実行させることにより学習時間を大幅に削減させた。学習アルゴリズムにはV-trace Actor Criticが使われているが、Atariに対して高いスコアを実現させている統合型Q学習アルゴリズムRainbowとのスコアの統一的な比較は十分にされていない。そのため、本研究ではRainbow含め他の学習アルゴリズムとのスコア比較を行った。また、探索手法として高分散に適したコンパクトな設計であるRNDとの統合を行い、統合前後での学習スコアの差異を基に、探索手法の選定の必要性について考察を行った。
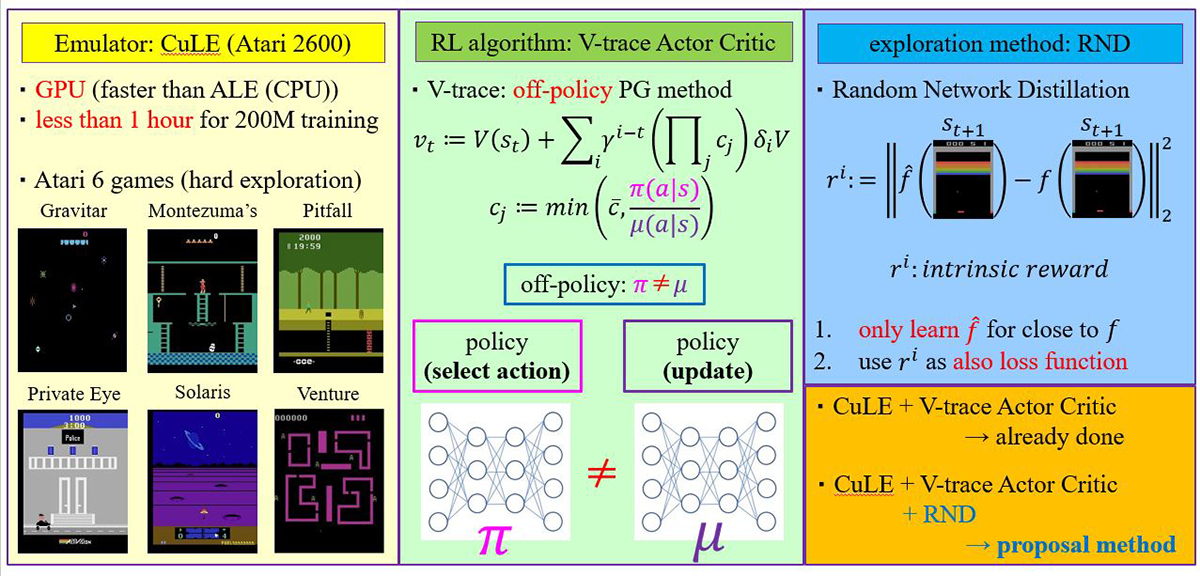
▲クリックすると拡大されます
Efficient library for hierarchical low rank approximation (Peter Spalthoff)
Dense matrices have a quadratic memory complexity and many operations on them have cubic scaling. This makes them prohibitively expensive for large scale operations. In many applications (covariance matrices, BEM...) a substructure of low rank blocks is found. This substructure can be exploited to create an efficient compression of the matrix, called hierarchical low rank approximation. On the resulting so-called Hierarchical Matrices, which only have linear storage complexity, all arithmetic operations (multiplication, inversion...) can be defined. These operations are also much faster with cloes to linear complexity. We are working on a modern, flexible library with distributed memory parallelization on heterogeneous nodes.
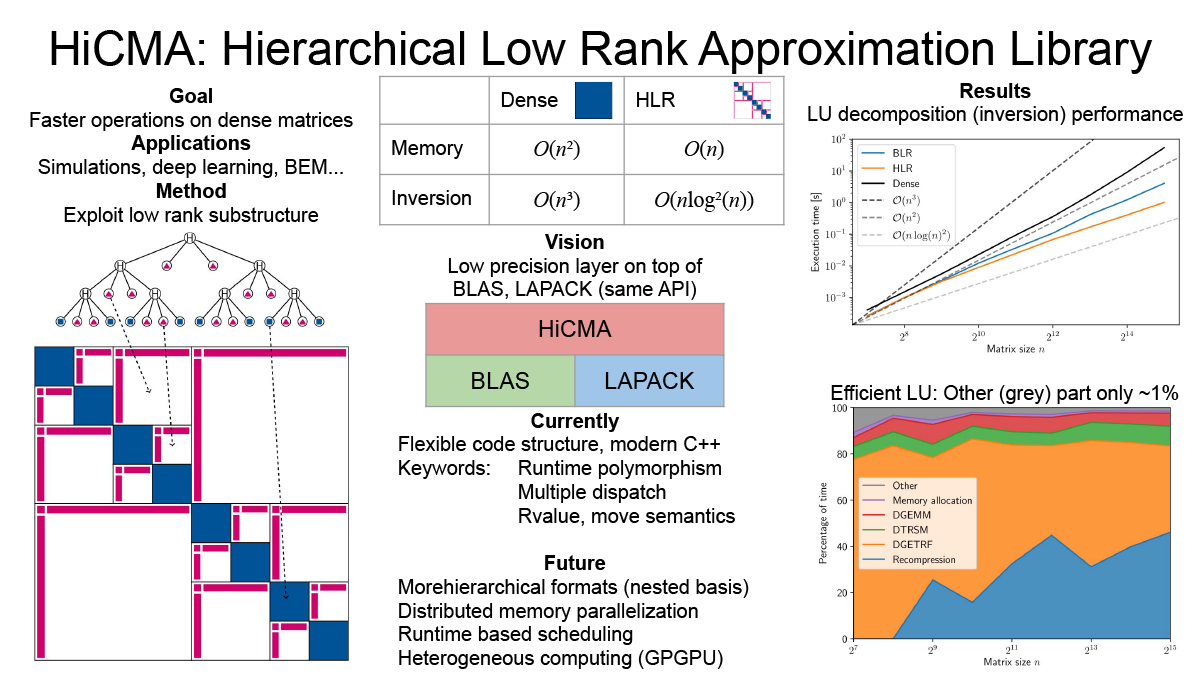
▲クリックすると拡大されます
2019年度学位論文研究 学士論文
確率的重み付け平均法のラージバッチ学習における有用性の検証 (所畑 貴大)
学習によるラージバッチ学習では、バッチサイズの増加と共に汎化性能が劣化する問題が経験的に知られている。本研究では、この問題を解決するために確率的重み付け平均法(Stochastic Weight Averaging ; SWA)に着目した。SWAは学習中にモデルのパラメータを定期的に抽出しそれらを平均化する手法であり、汎化性能の劣化の原因と考えられているSharpな解への収束を防ぐ効果が期待できる。本研究ではSWAをラージバッチ学習に適用することで汎化性能の改善効果を検証した。また、SWAを利用した並列深層学習手法であるSWAP(Stochastic Weight Averaging in Parallel)にも着目し、SWAPとラージバッチ学習における標準的な最適化手法の一つであるLARS(Layer-wise Adaptive Rate Scaling)を組み合わせた手法を提案及びその汎化性能の改善効果を検証した。
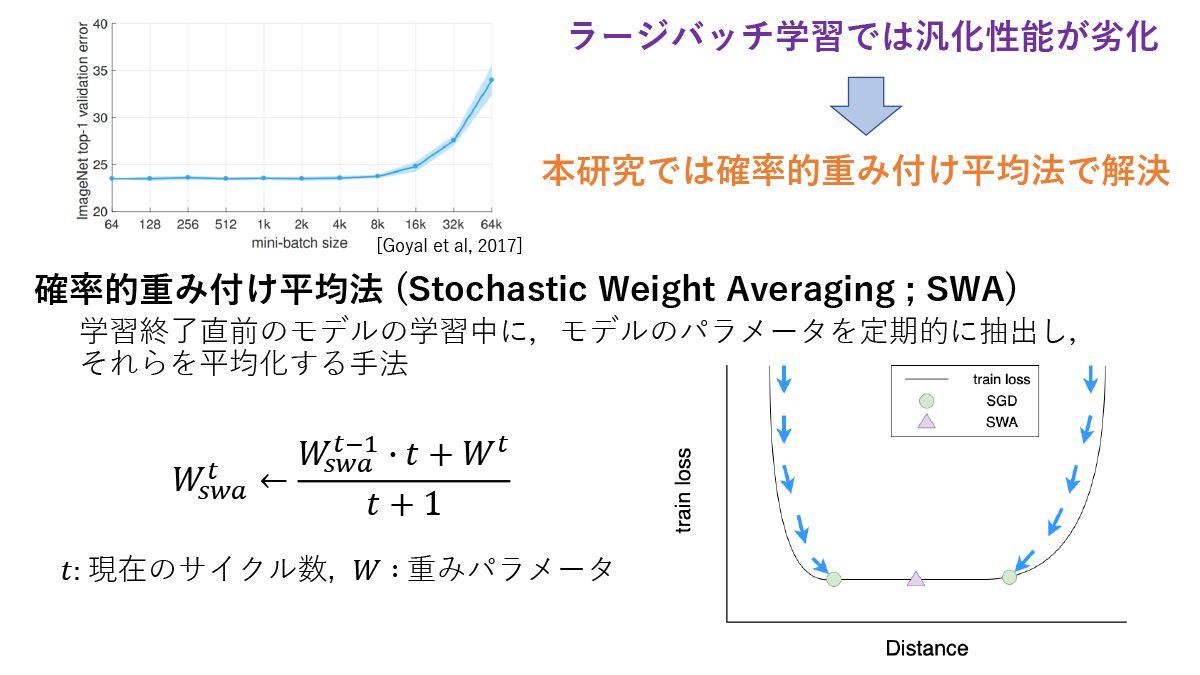
▲クリックすると拡大されます
情報行列を用いた深層ニューラルネットワークの汎化誤差推定 (星野 華)
近年,理論的観点,そして経験的観点から多くの汎化指標が提案されている.本研究では情報行列を用いた深層ニューラルネットワーク(DNN)の汎化指標,広く使える情報量基準(WAIC)に着目した.WAICは2010年に提案された汎化指標であるが,これの計算に必要なDNNにおける事後分布の推定が計算量とメモリ量の観点から困難なため,今まで大規模なDNNに用いた報告が未だなされていない.一方,近年急速に発展を遂げた情報行列の高速な近似手法と効率的な近似ベイズ推論手法を組み合わせることで,これらの問題を解決し,WAICを近似的に評価する方法を提案した.この近似的に推定されたWAICと,同じく情報行列を用いた汎化指標であるEmpirical TICをケンドールの順位相関係数で評価することで大規模な設定における有効性を検証した.
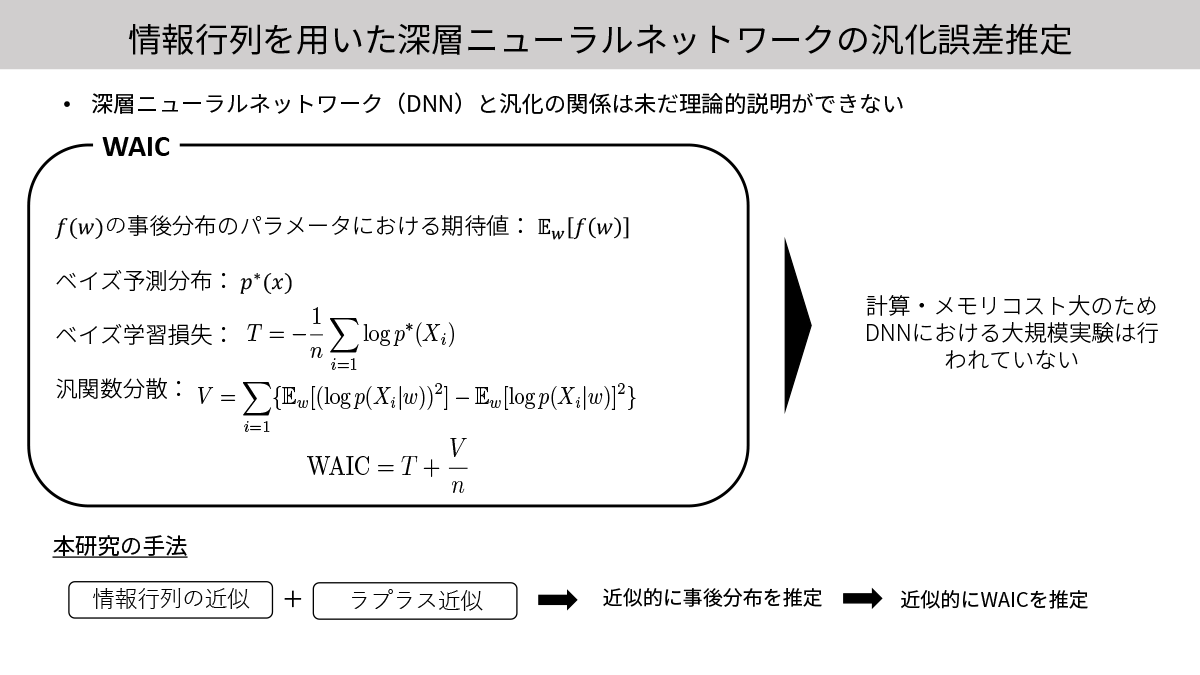
▲クリックすると拡大されます
2018年度学位論文研究 修士論文
畳み込みニューラルネットワークにおける低精度演算を用いた高速化の検証 (長沼 大樹)
Verification of speeding up using low precision arithmetic in convolutional neural network
The recent trend in convolutional neural networks (CNN) is to have deeper multilayered structures. While this improves the accuracy of the model, the amount of computation and the amount of data involved in learning and inference increases. In order to solve this problem, several techniques have been proposed to reduce the amount of data and the amount of computation by lowering the numerical precision of computation and data by utilizing the CNN's resistance to noise.
However, there is a lack of discussion on the relationship between parameter compression and speedup within each layer of the CNN.
In this research, we propose a method to speed up the inference by using half precision floating point SIMD instructions, by applying low precision to the learned model, in addition to reducing the data of the CNN model, and speeding up data access for layers that are computation-bound.
We examined the influence of CNN recognition accuracy, the speedup for each layer, and its reason, when we apply our method.
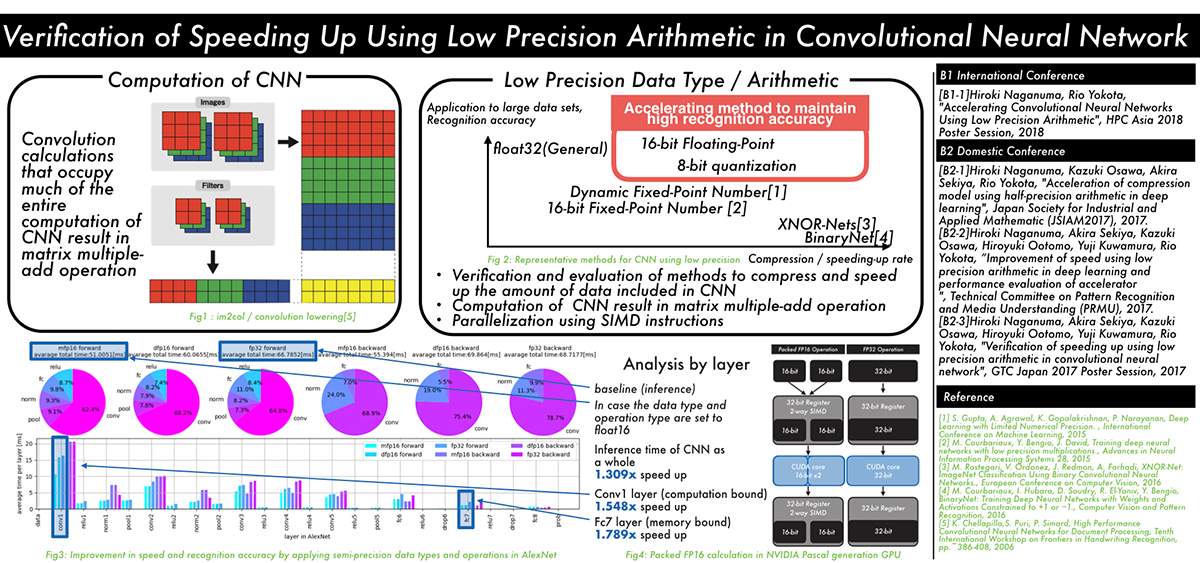
▲クリックすると拡大されます
大規模並列深層学習のための確率的最適化に基づいた目的関数の平滑化 (長沼 大樹)
Smoothing of the Objective Function in Stochastic Optimization for Large Scale Parallel Deep Learning
Classical learning theory states that when the number of parameters of the model is too large compared to the data, the model will overfit and the generalization performance deteriorates. However, it has been empirically shown that deep neural networks (DNN) can achieve high generalization capability by training with extremely large amount of data and model parameters, which exceeds the predictions of classical learning theory. One drawback of this is that training of DNN requires enormous calculation time. Therefore, it is necessary to reduce the training time through large scale parallelization. Straightforward data-parallelization of DNN degrades convergence and generalization. In the present work, we investigate the possibility of using second order methods to solve this generalization gap in large-batch training. This is motivated by our observation that each mini-batch becomes more statistically stable, and thus the effect of considering the curvature plays a more important role in large-batch training. We have also found that naively adapting the natural gradient method causes the generalization performance to deteriorate further due to the lack of regularization capability. We propose an improved second order method by smoothing the loss function, which allows second order methods to generalize as well as mini-batch SGD.
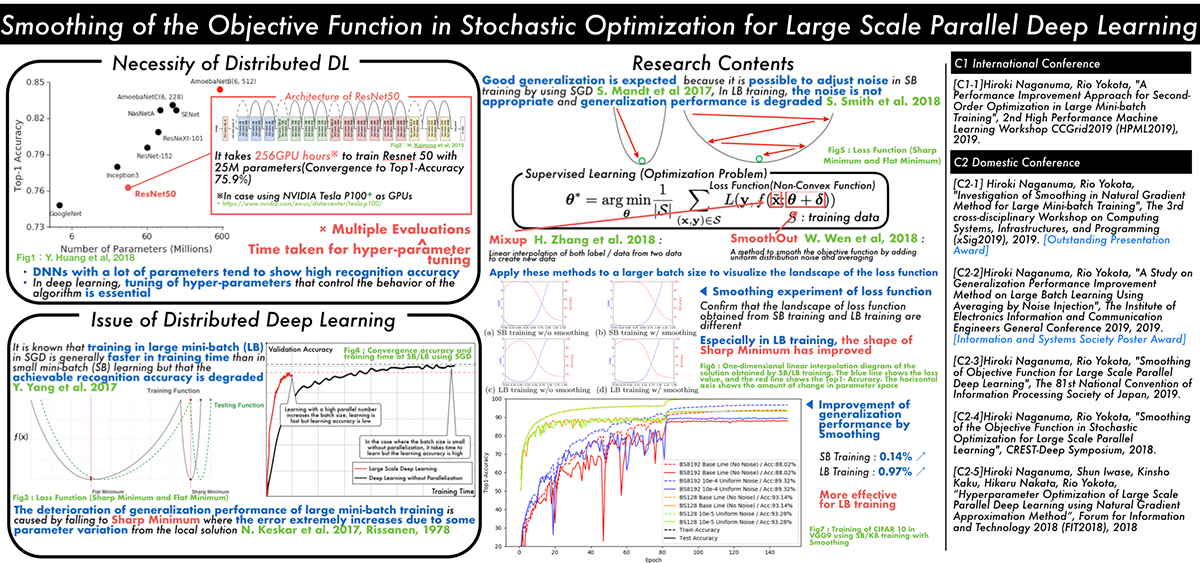
▲クリックすると拡大されます
2018年度学位論文研究 学士論文
帯域幅最適なGPU間AllReduce通信の階層化 (上野 裕一郎)
本研究では,データ並列・同期型分散深層学習で,損失関数のパラメータによる勾配の平均値を求めるために用いられるAllReduceと呼ばれる集団通信アルゴリズムに着目した.この通信は,MPI(Message Passing Interface)の集団通信の仕様に含まれているが,分散深層学習で用いられる大きなメッセージサイズの通信は,従来のHPCアプリケーションで使用されてきた通信とは異なり,未だ研究が不十分である.既存研究として,階層化を用いることで通信を改善できることが知られているが,どのような階層化が最適かは十分に調べられていない.本研究では,産総研「ABCIグランドチャレンジ」プログラムにより提供を受けた,AI橋渡しクラウド(ABCI)の計算リソースを用いて,網羅的に階層化通信の性能を評価した.
Yuichiro Ueno and Rio Yokota, "Exhaustive Study of Hierarchical AllReduce Patterns for Large Messages Between GPUs", in IEEE/ACM International Symposium in Cluster, Cloud, and Grid Computing (CCGrid 2019).
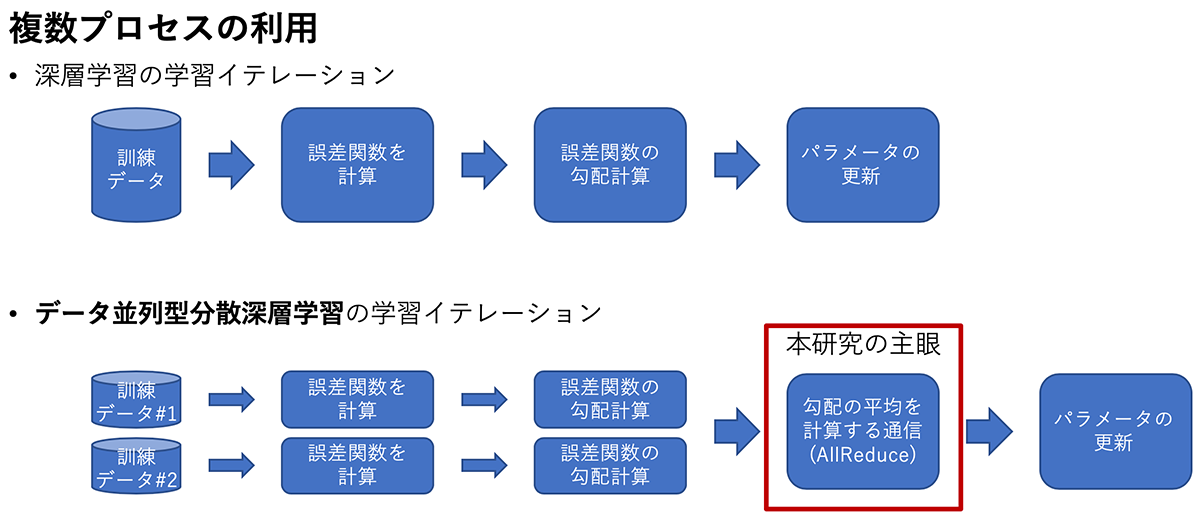
▲クリックすると拡大されます
SiameseNetworkによる筆者識別 (郭 林昇)
本研究では2入力間の特徴量を学習するSiameseNetworkと呼ばれる深層学習モデルを用いて筆者識別タスクを行うモデルの生成を行なった。NISTデータセットから取り出した筆者ごとの手書き数字を用いてモデルの学習を行い、同じくNISTデータセットから作成したテストデータに対して筆者識別タスクが可能であるモデルの生成に成功した。精度の検証も行なったが、クラス数の少ない場合には高い精度での識別が行えていたが、クラス数が多くなると精度が下がる傾向があり、内部表現の分割等による正則化を行い精度向上を目指すことが今後の課題である。
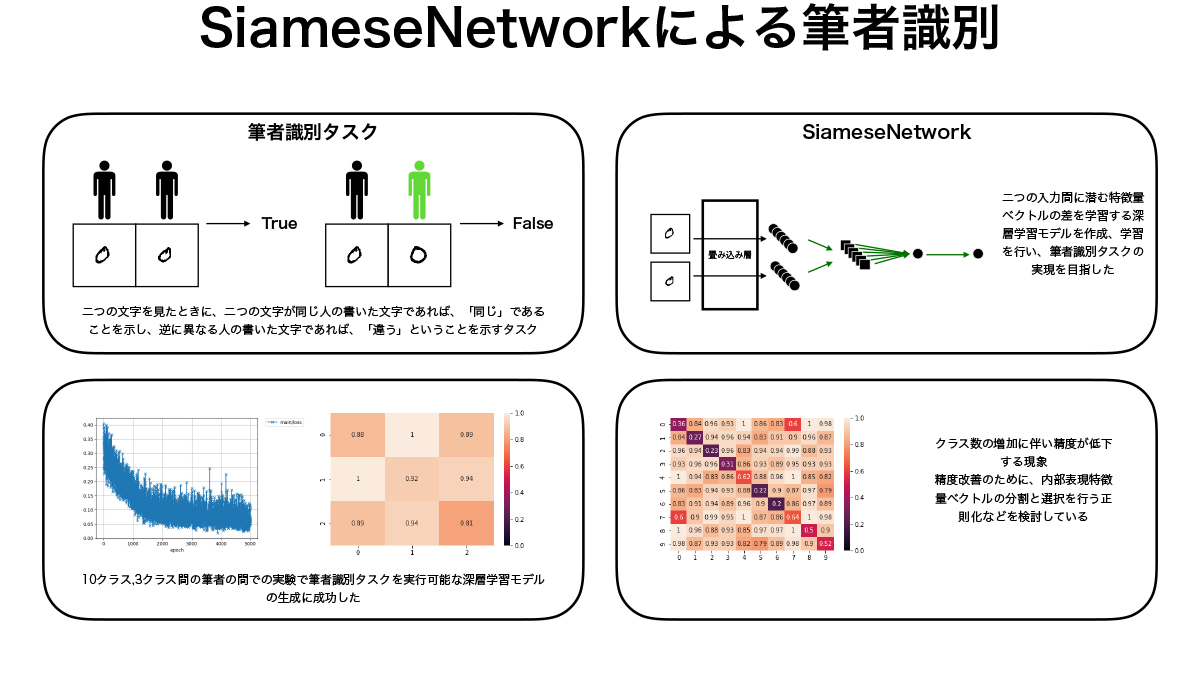
▲クリックすると拡大されます
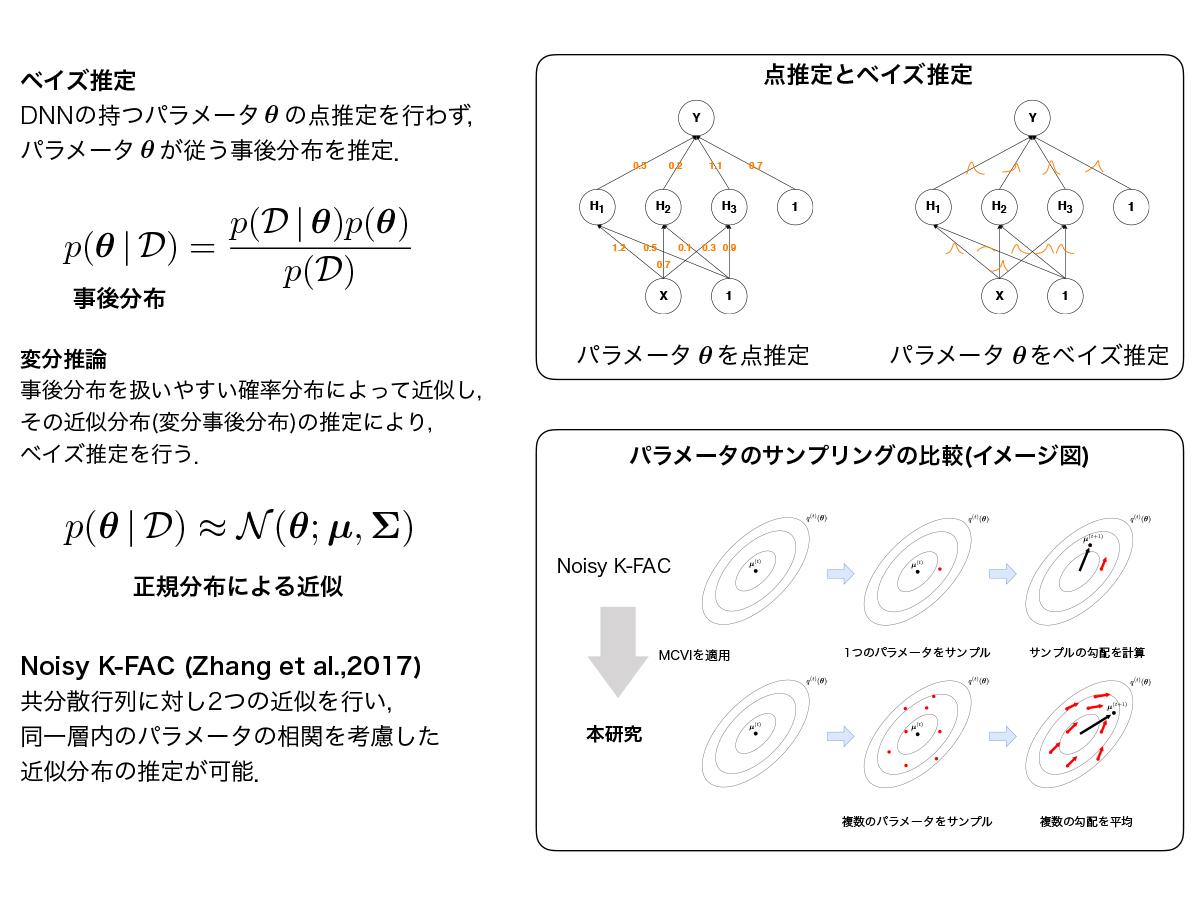
自然勾配法に基づくベイズ的深層学習に関する研究 (中田 光)
深層学習における変分事後分布に正規分布を仮定した変分推論では,変分事後分布の共分散行列の大きさがニューラルネットワークのパラメータ数に依存して大きくなるため,計算量やメモリ容量の観点からパラメータ間の相関を考慮した変分事後分布の推定は困難とされてきた.自然勾配法の効率的な近似手法であるK-FACを変分推論における最適化に用いたNoisy K-FACは,大規模なニューラルネットワークにおいても層ごとのパラメータの相関を考慮した変分事後分布の推定を可能とし,学習が汎化することが示されている.本研究ではNoisy K-FACに着目し,既存研究では明らかにされてこなかった、変分パラメータの探索にMCVIを適用した場合の検証を行なった.
▲クリックすると拡大されます