

Current Research Topics 2023
Pre-training of Large Language Models (LLM)
Yokota Lab is participating in large-scale pre-training projects using the world's largest supercomputers Aurora (63,744 GPU), Frontier (37,888 GPU), Fugaku (158,976 CPU), LUMI (20,480 GPU), Summit (27,648 GPU). We are also participating in a large-scale pre-training projects using domestic supercomputers such as ABCI (5,312 GPUs), TSUBAME (960 GPUs), and MDX (320 GPUs). Because LLM pre-training requires a huge amount of computational resources, the use of such supercomputers is essential. While researchers on the natural language processing side are experimenting with different data in each project, it is very important to have a group that can bridge the computational gap by efficiently running frameworks such as Megatron-DeepSpeed and GPT-NeoX, which serve as a common infrastructure, on these different supercomputers, and by providing expertise in building environments and stabilizing large-scale learning.

▲Click image to enlarge
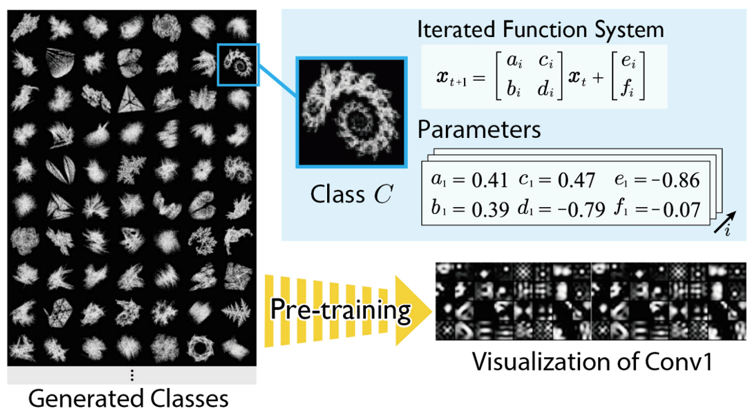
Pre-training of Large-scale Vision Models Using Synthetic Images
While linguistic data is subject to copyright and privacy issues, the same is true for image data. For large-scale real image data sets such as JFT and LAION, which are currently used for large-scale pre-training, ethical issues as well as legal compliance are important. However, fractal images generated from mathematical equations are free from such risks. In our joint research with AIST, we have observed that even with such artificial images, the pre-training effect is comparable (or superior) to that of Vision Transformer pre-training with real images, such as ImageNet-21k.

▲Click image to enlarge
Bayes Duality and its Application to Continual Learning
Current deep learning is not able to continuously train large models with the latest data. Transfer learning and fine-tuning is possible under limited conditions, but this problem is far from being solved. The application of Bayesian duality has the potential to greatly advance the study of continuous learning. In our joint research with RIKEN AIP, we are investigating forgetting-resistant continuous learning from both a mathematical and a high-performance computational perspective.
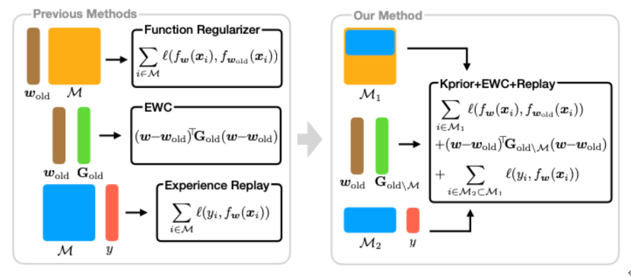
▲Click image to enlarge
Thesis 2022
Scaling up Pre-training with Synthetic Images (Sora Takashima)
In the context of image recognition tasks, the highest accuracy has been achieved by ViT pre-trained on very large real image datasets such as JFT-300M/3B. On the other hand, labeled real image datasets used for pre-training have many problems such as ethical and copyright issues, difficulties in collection and labeling, and oligopoly by some organizations, and it is difficult to control these problems by increasing the dataset size. In this study, we developed three hypotheses about the human-made image dataset for FDSL to pre-training ViT: 1) contours of objects in the image are important, 2) variations in image representation are important, and 3) scaling up can improve the pre-training effect. We constructed new datasets {ExFractalDB, RCDB, VisualAtom} to test each hypothesis, and conducted a comparative verification of the pre-training effect of each dataset.
▲Click image to enlarge
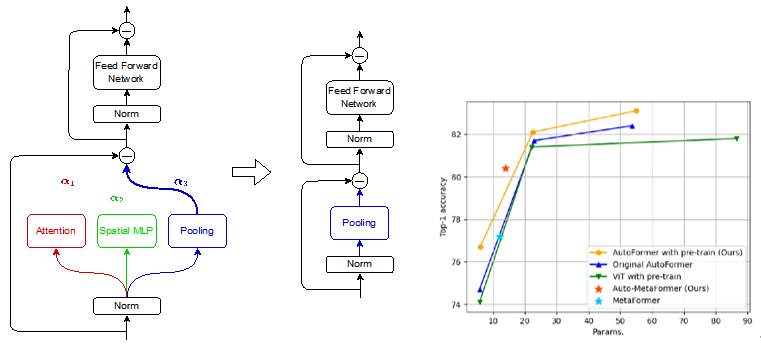
Model Reduction Effect of NAS during Finetuning of Vision Transformers (Xinyu Zhang)
Vision Transformers (ViT), an application of Transformer used in natural language processing, have surpassed traditional Convolutional Neural Networks (CNN) in image classification on ImageNet by pre-training on large datasets. However, the models are becoming so large to achieve high accuracy that they cannot even fit on a single GPU, which limits their usefulness during inference. In order to reduce the size of such large ViT models while keeping their performance, we utilize Neural Architecture Search (NAS), which makes it possible to automatically design architectures of deep neural networks. We propose a method called Auto-MetaFormer, which can automatically search for architecture of MetaFormer based on algorithm of DARTS by Liu et al. It uses a gradient based approach to search for architecture by training architecture weights along with model weights. Auto-MetaFormer succeeds in automatically searching the MetaFormer architecture, gaining a 2% increase in accuracy using the same number of parameters. For the same classification accuracy, the number of parameters also be further reduced by 20% compared to the manually designed architecture.
▲Click image to enlarge
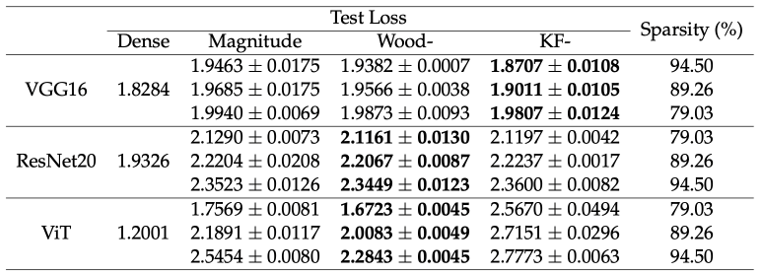
Neural Network Pruning based on Second-Order Information (Sixue Wang)
Nowadays, deep learning has demonstrated its ability to solve arduous tasks in different domains, such as computer vision, voice interaction, and natural language processing, but there is a huge gap between academia and industry when considering cost, efficiency and quality. Neural network pruning is a common technique to reduce the size of neural networks. It selects some redundant parameters and removes them all. The goal of this thesis is to exploit second-order information in neural network pruning in a practical manner. We demonstrate that second-order neural network pruning can achieve better or comparable results within similar computational resources.
▲Click image to enlarge
Large-Scale Self-Supervised Learning of Driving Videos (Tomoya Takahashi)
In automated driving, recognition of the external environment obtained from cameras and lidar is the core of technology to ensure safety. Although the accuracy of these recognitions has been dramatically improved with the advent of deep learning, it is still not sufficient to realize fully automated driving. One of the reasons for this is that while a huge amount of vehicle driving data can be collected, the annotation cost of true-value labels is high, and it is difficult to prepare enough teacher data for learning. In this study, we aim to construct a recognition model that is robust to temporal changes in the visibility of objects by pre-training running videos using self-supervised learning on a pixel-by-pixel basis and by using optical flow. As a downstream task to evaluate the effect of the pre-training, we evaluated semantic segmentation using CityScapes. As a result, we found that accuracy varied greatly depending on the definition of neighborhood when comparing image pixels. In addition, we found that the accuracy can be further improved by using a mask to remove false positive examples, in which a pixel pair that is not originally a positive example is judged to be a positive example.
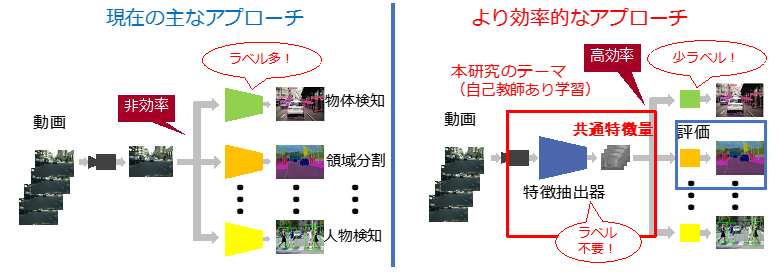
▲Click image to enlarge
Change Detection by Visual SLAM Using Deep Learning (Kai Okawa)
Visual SLAM, which estimates the camera's self-position and reconstructs a 3D map of the surrounding area from a sequence of images, is one of the most important fundamental technologies in an AI society, playing the role of "eyes" in automated driving, AR/MR, and robotics. In recent years, methods capable of robustly estimating self-position and 3D maps in real time have emerged in Visual SLAM research. In addition, methods incorporating deep learning, which has evolved remarkably in recent years, have been proposed, enabling more accurate self-position estimation and 3D map restoration. However, after a certain period of time has passed since the 3D map was created, the actual scene may change, and discrepancies may arise between the 3D map and the actual scene. Such discrepancies degrade the accuracy of Visual SLAM and cause the 3D map to become bloated due to the accumulation of old information. In this study, we propose a change detection method for 3D maps at two different times, using information obtained from DROID-SLAM, which estimates a change mask using the dense depth information estimated by DROID-SLAM and the optical flow estimated by a regression-type neural network. In addition, a new change-aware objective function is introduced to optimize the change mask. Furthermore, a synthetic image dataset suitable for this study was created, and experiments were conducted. Through the experiments, we confirmed that it is possible to estimate the change mask for the two-time 3D map estimated by DROID-SLAM.
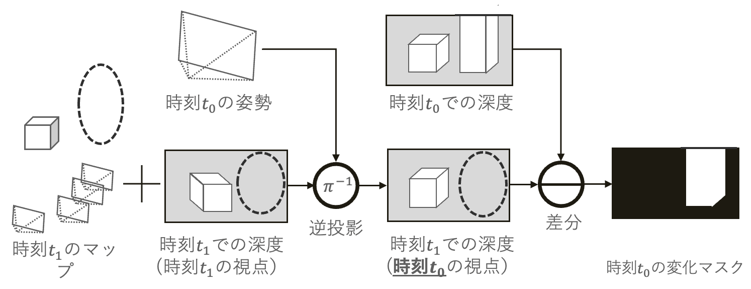
▲Click image to enlarge
Bachelors Thesis 2022
Gradient Preconditioning in Second-Order Optimization of Deep Learning (Satoki Ishikawa)
Gradient preconditioning using curvature matrices (Hessian matrix, Fisher information matrix, second-order moments) has become an important technique in a wide range of deep learning tasks. Gradient preconditioning is used in various domains, including second-order optimization to speed up deep learning optimization, continuous learning, branch-and-bound pruning, and Bayesian inference. In second-order optimization of deep learning, gradient preconditioning is performed after approximating the curvature matrix. Various types of approximation algorithms have been proposed for this purpose, but the differences in their characteristics have rarely been investigated. Therefore, this study compares these algorithms from two perspectives: computational aspects such as memory consumption and computation time, and training convergence. Since the overall learning time is determined by the product of the computation time per step and the number of steps required for convergence, it is very important to examine both of these characteristics. The results show that many second-order optimization methods, such as KFAC and Shampoo, have the potential to be particularly useful for learning at large batch sizes. We also found that second-order optimization methods such as SENG and SMW-NG, which use the SMW formula for the inverse matrix computation, have different properties than other methods.
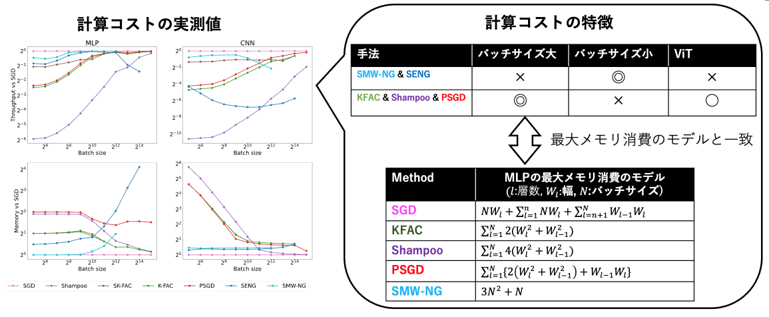
▲Click image to enlarge
Pre-training of Vision Transformers Using Newton Fractals (Toshiki Omi)
In the field of image recognition, the mainstream method is to use a large-scale natural image dataset such as JFT-300M/3B for pre-training, followed by fine-tuning with the data of the target task. It is known that the larger the dataset used for pre-training, the higher the image classification and object recognition performance can be obtained, making the choice of which dataset to use for pre-training an important issue. However, natural image datasets pose many problems, including the collection of large numbers of images, labeling costs, copyright issues, content bias issues, and issues of fairness and offensive labels. In this study, we pre-trained the Vision Transformer Tiny model using an image dataset consisting of Newton Fractal images generated by the Newton method, and evaluated the performance of the dataset by the accuracy of the fine tuning task of CIFAR-10/100. The performance of the dataset was evaluated by the accuracy of CIFAR-10/100 fine tuning task. In addition, we conducted similar experiments on FractalDB and ExFractalDB, which are the conventional fractal datasets, and ImageNet, which is a natural image dataset, to compare the performance of the conventional method. As a result, the pre-training effect of the Newton Fractal image dataset was confirmed. As with the conventional FDSL dataset, the performance of the dataset consisting of black-and-white images was higher than that of color or grayscale images, and the performance was improved by changing the image generation conditions. Although the pre-training effect was lower than that of ImageNet, the pre-training effect was higher than that of the image representations used in conventional FDSL methods.

▲Click image to enlarge
Accelerating Quantum Vortex Simulations with Fast Multipole Methods (Tomokazu Saito)
Fluids at cryogenic temperatures have zero viscosity due to quantum effects. Such fluids are called superfluids. The physical properties of superfluids are important from an engineering viewpoint, but for applications, it is necessary to elucidate complex phenomena such as turbulence in superfluids. However, experiments on superfluids require expensive equipment because the fluid must be maintained at extremely low temperatures. Therefore, it is important to analyze the behavior of turbulence by simulation. However, methods that require a very fine mesh, such as the finite element method, require an enormous amount of time. Quantum turbulence is am inviscid fluid consisting of many vortex threads, and it is effective to use the Vortex Method. In this study, FMM, which calculates the interaction between vortex particles based on the Biot-Savart law, was implemented on CPUs and GPUs, and its calculation speed and accuracy were evaluated. However, we were able to confirm that the error decreases with increasing P in the implementation. Furthermore, we confirmed that the error converges to a constant value around 274 periodic images when the number of particles is 104 and the order of FMM is P = 10, while FMM can calculate periodic boundary conditions with minimum overhead.

▲Click image to enlarge
Thesis 2021
Off-Policy Inverse Reinforcement Learning via Distribution Matching (Hana Hoshino)
Inverse Reinforcement Learning (IRL) is attractive in scenarios where reward engineering can be tedious. However, prior IRL algorithms use on-policy transitions, which require intensive sampling from the current policy for stable and optimal performance. This limits IRL applications in the real world, where environment interactions can become highly expensive. To tackle this problem, we present Off-Policy Inverse Reinforcement Learning (OPIRL), which (1) adopts off-policy data distribution instead of on-policy and enables significant reduction of the number of interactions with the environment, (2) learns a reward function that is transferable with high generalization capabilities on changing dynamics, and (3) leverages mode-covering behavior for faster convergence. We demonstrate that our method is considerably more sample efficient and generalizes to novel environments through the experiments. Our method achieves better or comparable results on policy performance baselines with significantly fewer interactions. Furthermore, we empirically show that the recovered reward function generalizes to different tasks where prior arts are prone to fail.
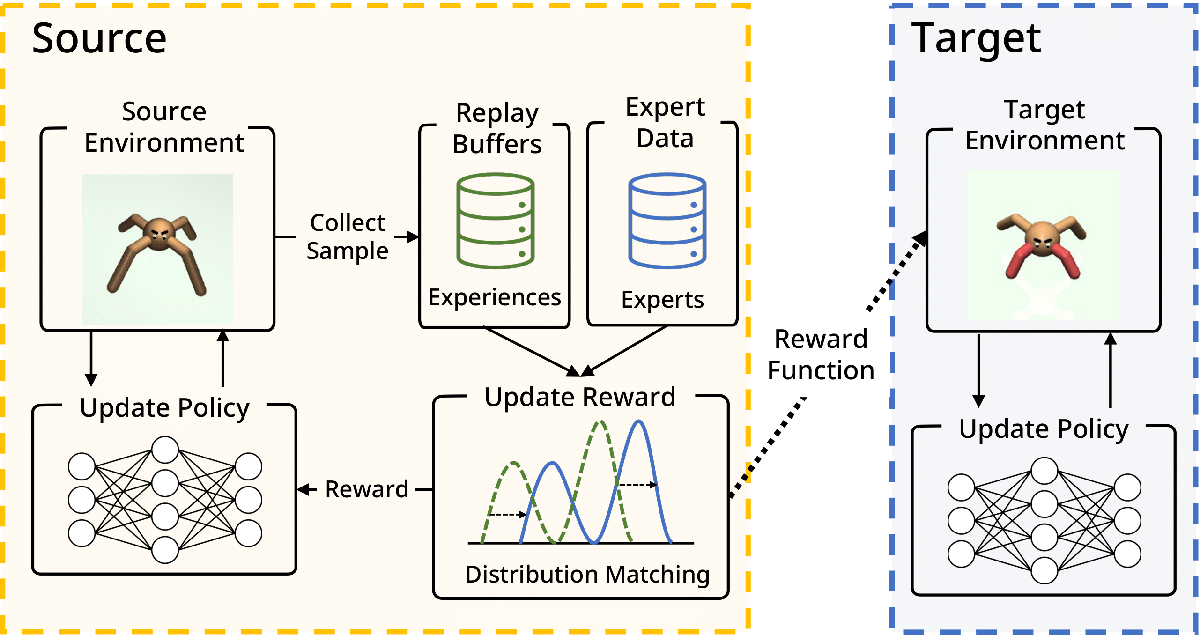
▲Click image to enlarge
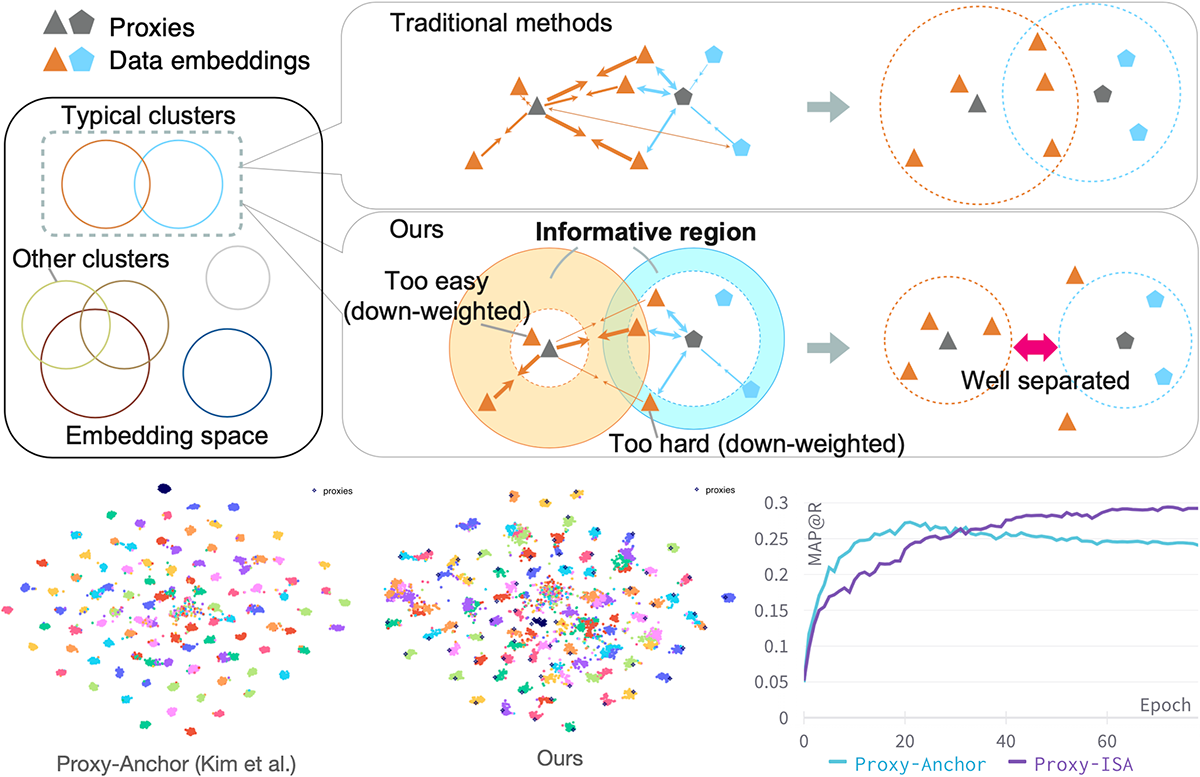
Informative Sample-Aware Proxy for Deep Metric Learning (Aoyu Li)
Metric Learning is one if the core fundamental tasks of machine learning. In deep metric learning (DML), the proxy-based methods are drawing more and more attention recently because of their flexibility and efficiency while maintaining higher performance. In this work, we propose a novel proxy-based method combined with class-dependent dynamic weighting, called Informative Sample-Aware Proxy (Proxy-ISA).
Proxies, which are class-representative points in the representation space, receive updates based on proxy-sample similarities as sample representations do. In existing methods, it may be possible that a relatively small number of samples producing large gradient magnitudes (i.e., hard samples) and a relatively large number of samples producing small gradient magnitudes (i.e., easy samples) play a major part in the update. Based on the assumption that acquiring too much sensitivities to such extreme sets of samples would deteriorate the generalization ability, the proposed Proxy-ISA directly modifies a gradient weighting factor to each sample. In this work, we first design a method to estimate the learned class-related region to acquire the information of class hardness. By defining the hard and easy samples adaptively to the class hardness, each proxy identifies its own hard and easy samples and reduces their weighting factors with a scheduled threshold function, so that the model acquires more sensitivity to the intermediate samples, which is called "informative" samples. Furthermore, we incorporate the idea of active learning to emphasize the informative samples dynamically according to the learning step, and the dynamic weights are assigned separately for positive pairs and negative pairs. Extensive experiments on the CUB-200-2011, Cars-196, Stanford Online Products and In-shop Clothes Retrieval datasets demonstrate superiority of Proxy-ISA over the state-of-the-art methods.
▲Click image to enlarge
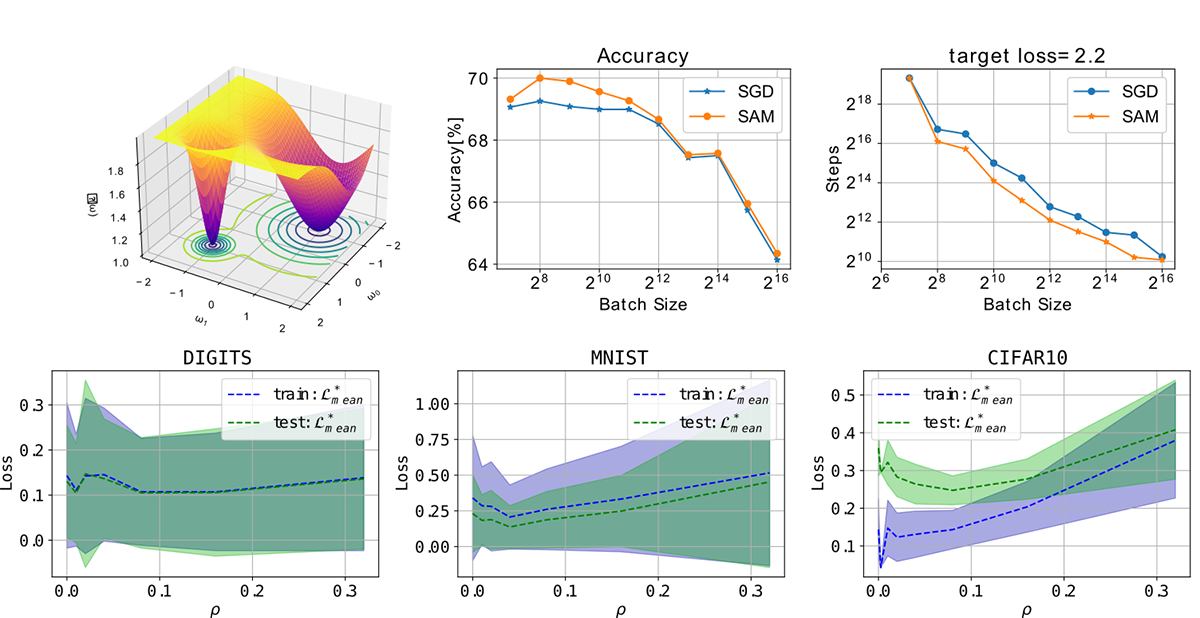
On the generalization gap of SAM optimizers for very large batch sizes (Elvin Munoz)
The generalization properties of a trained network are highly tied to the geometrical shape of the loss function evaluated at the parameters of the model; it has been found that flat minima increase the generalization properties of a neural network. Due to the stochasticity of most optimizers such as SGD, normally a flat minima will be found rather than a sharp minima. However, as we increase the batch size and thus reduce the stochasticity of the training process, it becomes more likely to fall into a sharp minima. There have been many methods that have been devised to counteract this effect and obtain high generalization properties even when using large batches, one of such methods is SAM (Sharpness-aware minimization). This method has been proven to improve the generalization properties of trained neural networks in the small-mid range of batch sizes and even it has been found to work in distributed training. However, a more in-detail study of its capabilities at higher batch sizes is needed; moreover this method introduces a new hyperparameter (neighborhood size) that needs to be tuned. The main goal of this work was to shed some light at the behavior of this optimizer when using a large batch (reaching almost full batch) and a study of the behavior of the neighborhood size for proper tuning.
▲Click image to enlarge
Thesis 2020
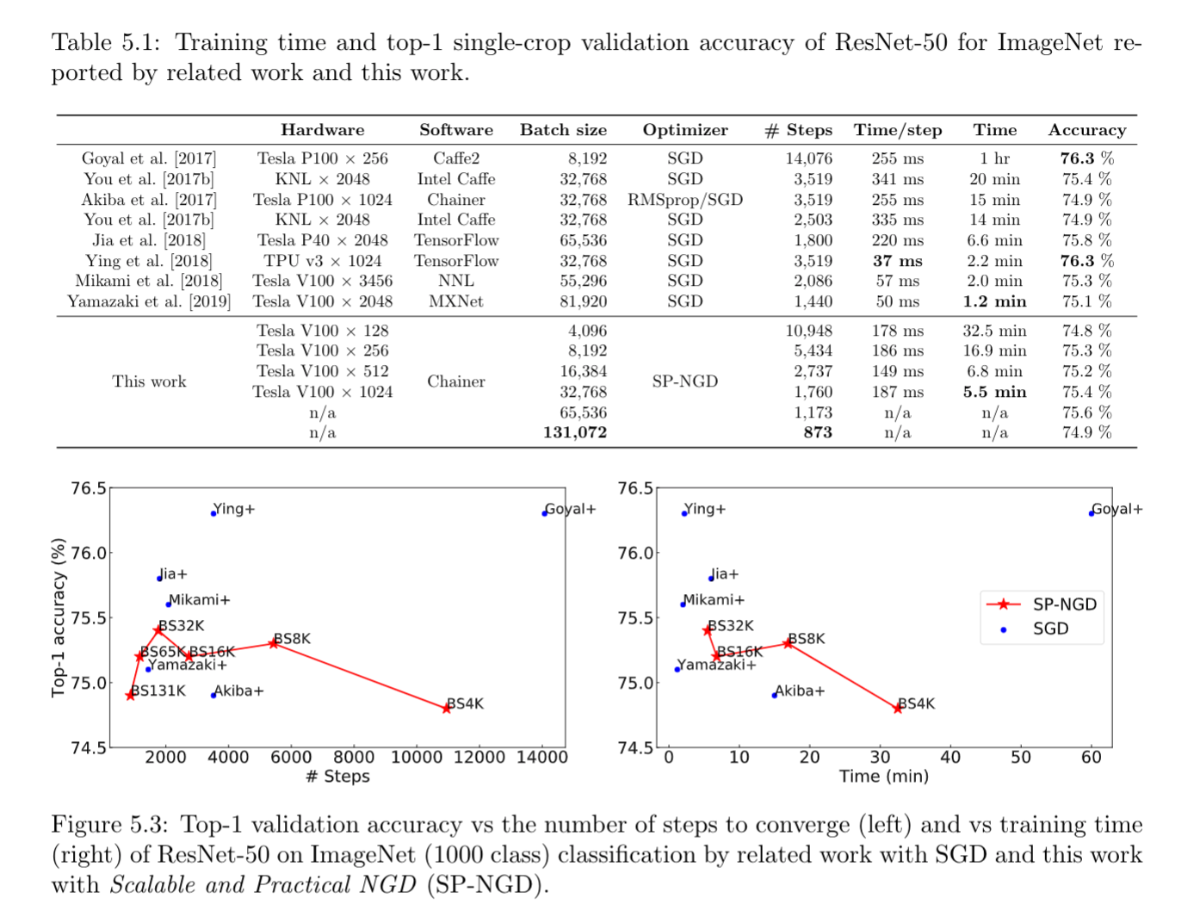
Second-order Optimization for Large-scale Deep Learning(Kazuki Osawa)
Large-scale distributed training of deep neural networks results in models with worse generalization performance as a result of the increase in the effective mini-batch size. Previous approaches attempt to address this problem by varying the learning rate and batch size over epochs and layers, or ad hoc modifications of Batch Normalization. We propose Scalable and Practical Natural Gradient Descent , a principled approach for training models that allows them to attain similar generalization performance to models trained with first-order optimization methods, but with accelerated convergence. Furthermore, SP-NGD scales to large mini-batch sizes with a negligible computational overhead as compared to first-order methods. We evaluate SP-NGD on a benchmark task where highly optimized first-order methods are available as references: training a ResNet-50 model for image classification on the ImageNet dataset. We demonstrate convergence to a top-1 validation accuracy of 75.4% in 5.5 minutes using a mini-batch size of 32,768 with 1,024 GPUs, as well as an accuracy of 74.9% with an extremely large mini-batch size of 131,072 in 873 steps of SP-NGD.
▲Click image to enlarge
Thesis 2019
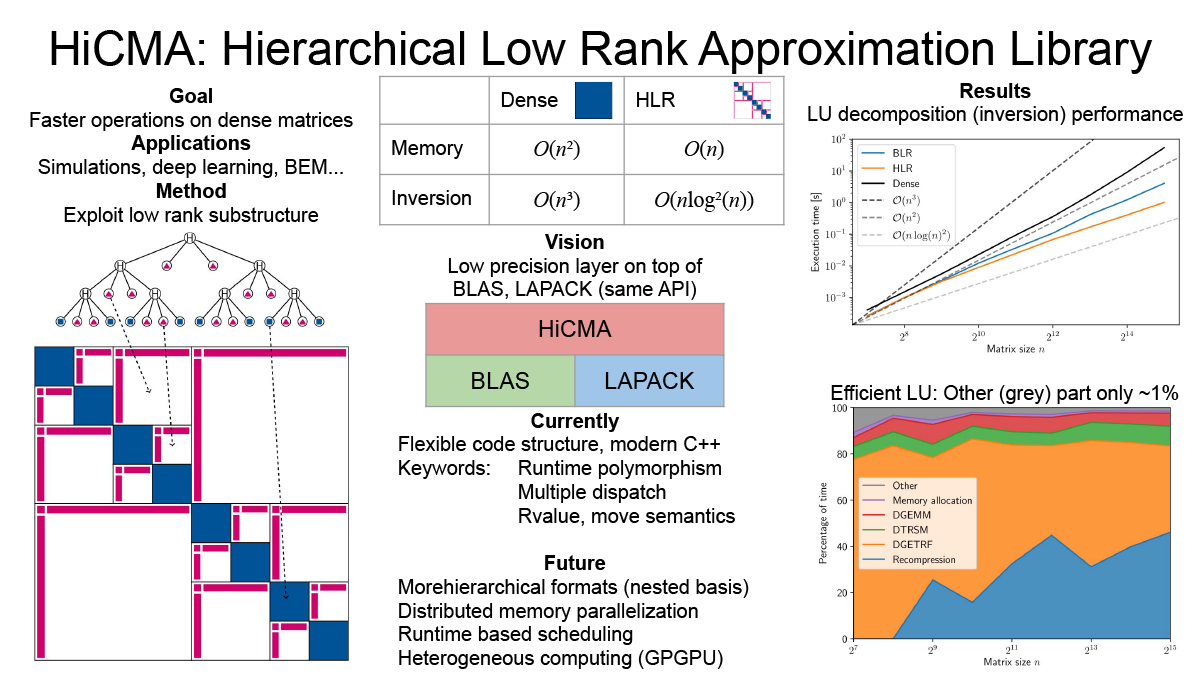
Efficient library for hierarchical low rank approximation (Peter Spalthoff)
Dense matrices have a quadratic memory complexity and many operations on them have cubic scaling. This makes them prohibitively expensive for large scale operations. In many applications (covariance matrices, BEM...) a substructure of low rank blocks is found. This substructure can be exploited to create an efficient compression of the matrix, called hierarchical low rank approximation. On the resulting so-called Hierarchical Matrices, which only have linear storage complexity, all arithmetic operations (multiplication, inversion...) can be defined. These operations are also much faster with cloes to linear complexity. We are working on a modern, flexible library with distributed memory parallelization on heterogeneous nodes.
▲ Click image to enlarge
Thesis 2018
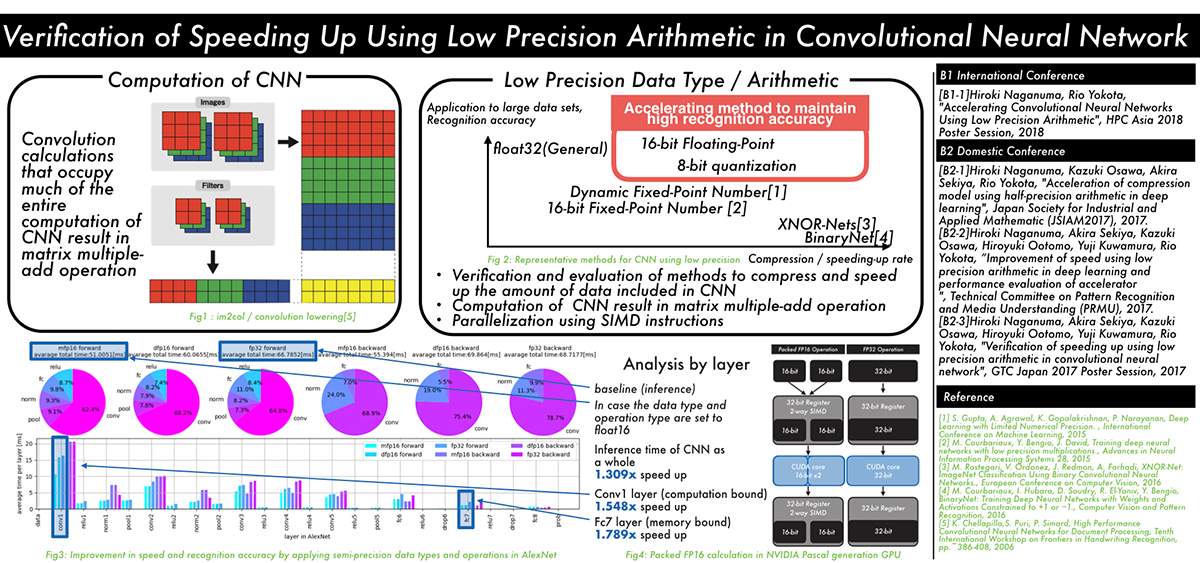
Verification of speeding up using low precision arithmetic in convolutional neural network (Hiroki Naganuma)
The recent trend in convolutional neural networks (CNN) is to have deeper multilayered structures. While this improves the accuracy of the model, the amount of computation and the amount of data involved in learning and inference increases. In order to solve this problem, several techniques have been proposed to reduce the amount of data and the amount of computation by lowering the numerical precision of computation and data by utilizing the CNN's resistance to noise.
However, there is a lack of discussion on the relationship between parameter compression and speedup within each layer of the CNN.
In this research, we propose a method to speed up the inference by using half precision floating point SIMD instructions, by applying low precision to the learned model, in addition to reducing the data of the CNN model, and speeding up data access for layers that are computation-bound.
We examined the influence of CNN recognition accuracy, the speedup for each layer, and its reason, when we apply our method.
▲ Click image to enlarge
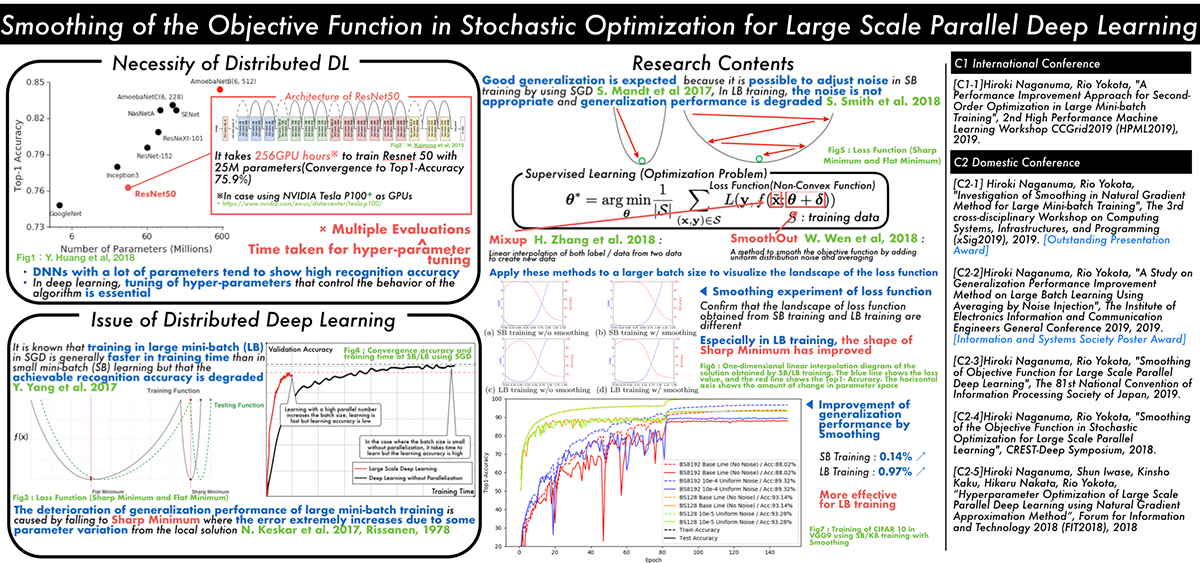
Smoothing of the Objective Function in Stochastic Optimization for Large Scale Parallel Deep Learning (Hiroki Naganuma)
Classical learning theory states that when the number of parameters of the model is too large compared to the data, the model will overfit and the generalization performance deteriorates. However, it has been empirically shown that deep neural networks (DNN) can achieve high generalization capability by training with extremely large amount of data and model parameters, which exceeds the predictions of classical learning theory. One drawback of this is that training of DNN requires enormous calculation time. Therefore, it is necessary to reduce the training time through large scale parallelization. Straightforward data-parallelization of DNN degrades convergence and generalization. In the present work, we investigate the possibility of using second order methods to solve this generalization gap in large-batch training. This is motivated by our observation that each mini-batch becomes more statistically stable, and thus the effect of considering the curvature plays a more important role in large-batch training. We have also found that naively adapting the natural gradient method causes the generalization performance to deteriorate further due to the lack of regularization capability. We propose an improved second order method by smoothing the loss function, which allows second order methods to generalize as well as mini-batch SGD.
▲ Click image to enlarge